Go 基础
参考官方网站,GOPL,STD,源代码,Go 语言设计与实现。
Tutorial
Hello, World
使用 go run 编译运行程序,go build 编译程序,go doc 查看文档。
某些标记之后的换行符会被转换为分号,因此换行符的位置对于正确解析 Go 代码至关重要。例如,函数的左括号 { 必须与函数声明的结尾在同一行,否则会报错 unexpected semicolon or newline before {。而在表达式 x + y 中,可以在 + 运算符之后换行,但不能在之前换行。
1 | func main() { |
Command-Line Arguments
可以使用 os.Args 变量获取命令行参数,该变量是一个字符串切片。os.Args[0] 是命令本身,剩余元素是程序启动时用户传递的参数。使用 var 声明语句定义变量,变量可以在声明时进行初始化。如果未显式初始化,则隐式初始化为该类型的零值(zero value),数值类型为 0,字符串类型为空串 ""。
for 语句是 Go 中唯一的循环语句,可以充当其他语言中常规的 for、while 循环以及无限循环。Go 语言不允许未使用的局部变量,否则会报错 declared and not used。使用 += 在循环中拼接字符串的开销较大,每次都会生成新字符串,而旧字符串则不再使用等待 GC,可以使用 strings.Join 方法提升性能,一次性拼接所有字符串。
1 | func main() { |
以下几种声明变量的方式都是等价的。第一种简洁但只能在函数中使用,而不能用于包级变量,第二种使用默认初始化,第三种形式仅在声明多个变量时使用,第四种仅在声明类型和初始值类型不同时使用。
1 | s := "" |
Finding Duplicate Lines
input.Scan() 读取下一行数据并移除行尾的换行符,可以调用 input.Text() 方法获取结果。map 的迭代顺序未明确指定,但在实际操作中是随机的,这种设计是有意为之,防止程序依赖特定的顺序。map 是一个由 make 创建的数据结构的引用(reference),当将 map 作为参数传递时,函数会收到引用的副本。
1 | func main() { |
Animated GIFs
const 常量的值必须是数字、字符串或者布尔值。以下程序使用 web 方式可以正常显示图像,但是如果使用 ./main > out.gif 重定向输出的方式,则在 Windows 中不能正常显示。因为 Windows 标准输出默认以文本模式处理数据,会修改输出的数据从而导致图像损坏。
1 | var palette = []color.Color{color.White, color.Black} |
Fet ching URLs Concurrently
1 | func main() { |
A Web Server
1 | func main() { |
Loose Ends
switch 语句的 case 不需要显式使用 break,默认不会 fallthrough 到下一个 case。可以省略 switch 之后的操作数,此时等价于 switch true。和 for 和 if 一样,在 switch 之后可以跟一个简单语句。
1 | func Signum(x int) int { |
Program Structure
Names
名称以字母(Unicode 字母)或下划线开头,可以包含任意数量的字母、数字和下划线,大小写敏感。关键字(keywords)不可作为名称被使用,而预声明(predeclared)的名称(内置常量、类型和函数)可以重新声明,但是存在混淆的风险。在函数内声明的实体仅在函数内可见,在函数外声明的实体包可见,名称的首字母大写则在包外可见。包名总是小写的,实体命名使用驼峰命名法。
Declarations
声明(declaration)命名一个程序实体,有四种主要的声明类型,var、const、type 和 func。Go 程序存储在以 .go 为后缀的文件中,每个文件开头都有包声明,之后是导入声明,然后是以任意顺序排列的包级(package-level)的类型、变量、常量和函数声明。函数的返回值列表是可选的(多个返回值构成列表),如果不返回任何值则可以省略。
Variables
变量声明的通用形式为 var name type = expression。如果省略 type 则类型由表达式推断,如果省略 = expression 则必须显式指定类型,初始值为该类型的零值。数值类型为 0,字符串类型为空串 "",布尔类型为 false,接口和引用类型(切片、指针、哈希表、通道和函数)为 nil。像数组或者结构体聚合类型的元素或字段的零值就是自身的零值。
零值机制确保变量始终有其类型所定义的明确值,Go 语言中不存在未初始化变量的概念。可以同时声明一组变量,如果省略类型则可以同时声明不同类型的变量。包级变量会在 main 函数开始之前初始化,局部变量在声明时初始化。
1 | var i, j, k int // int, int, int |
Short Variable Declarations
在函数中可以使用简短变量声明(short variable declaration)的形式声明和初始化局部变量,形式为 name := expression。简短变量声明常用于声明和初始化大多数局部变量,而 var 声明常用于变量类型和表达式类型不同、或者稍后赋值且初始值不重要的局部变量。
1 | i := 100 // an int |
区分 := 是声明而 = 是赋值。需要注意,如果简短变量声明中的变量已经在相同词法块(lexical block)中被声明过,那么该声明相当于对该变量赋值。而且简短变量声明必须至少声明一个新变量,否则代码将无法通过编译。
1 | f, err := os.Open(infile) |
Pointers
指针(pointer)是变量的地址(address),可以通过指针间接地读写变量的值,而无需知晓变量的名称。指针的零值是 nil,如果指针指向某个变量则其值必然不为 nil。两个指针相等仅当它们指向相同的变量或者都为 nil。
1 | x := 1 |
函数返回局部变量的地址是安全的,即使函数调用返回该局部变量 v 仍会存在。由编译器逃逸分析确定,该变量会在堆上分配。根据静态分析知识,为保证安全性,分析肯定是偏向误报(Sound)而不是漏报(Complete)。每次调用函数 f 返回的值都不同。每次获取变量的地址或者复制指针时,都会为该变量创建新的别名(aliases),*p 是 v 的别名。
1 | var p = f() |
1 | var n = flag.Bool("n", false, "omit trailing newline") |
The new Function
另一种创建变量的方式是使用内置函数 new,表达式 new(T) 创建类型为 T 的未命名变量,将其初始化为类型 T 的零值,返回类型为 *T 的地址值。使用 new 创建的变量和普通局部变量没有区别,只是后者需要显式获取地址。
1 | func newInt() *int { |
通常每次调用 new 都会返回具有唯一地址的不同变量,例外情况是,如果两个变量的类型不携带任何信息且大小为零(例如 struct{} 或 [0]int),则根据实现的不同可能会具有相同的地址(实测得到的是不同地址)。由于 new 是内置函数而不是关键字,所以可以被重新定义为其他东西,不过此时不能在 delta 中使用内置的 new 函数。
1 | func delta(old, new int) int { return new - old } |
Lifetime of Variables
变量的声明周期是指其在程序执行过程中的存活时间。包级变量在整个程序执行过程中存活,局部变量在声明时创建,在不被引用时回收(GC 可达性分析)。因为变量的生命周期取决于可达性,所以局部变量在函数返回之后仍有可能存活。编译器会决定将变量分配到堆中还是栈中,这一决定并非取决于使用 var 还是 new 来声明变量(Pointers 小节中提到过的逃逸分析)。例如,下面示例中 x 必须在堆上分配,而 y 可以在栈上分配。
1 | var global *int |
Assignments
Go 语言中仅有后置 x++ 和 x-- 而没有前置写法,而且该操作被视为语句而不是表达式,所以不能将其赋值给变量或者参与运算。
Tuple Assignment
元组赋值(tuple assignment)允许一次为多个变量赋值,在对任何变量更新之前,所有右侧表达式都会被计算出来。如果函数具有多个返回值,则赋值语句左侧必须包含相同数量的变量,可以使用 _ 忽略不需要的值。
1 | x, y = y, x |
Assignability
当值能够赋值给变量的类型时,该赋值操作才是合法的,不同类型有不同的赋值规则。只有当两个变量可以相互赋值时,它们才能够使用 == 和 != 进行比较。(Java 中引用类型之间总是可以使用该运算符相互比较)
Type Declarations
类型声明形如 type name underlying-type,用于定义一个新的具有某个底层类型(underlying type)的命名类型(named type)。即使两个类型具有相同的底层类型,它们也是不同的类型,不能直接比较或组合,而需要使用 T(x) 进行显式类型转换。命名类型将底层类型的不同使用方式区分开来,避免不同使用方式之间混淆。
1 | type Celsius float64 |
Packages and Files
在 Go 语言中,包的作用与其他语言中的库或模块相同,支持模块化、封装、独立编译和代码复用。一个包的源代码在一个或多个 .go 文件中,通常这些文件位于一个目录中,该目录的名称以导入路径结尾。例如 gopl.io/ch1/helloworld 包的文件存储在 $GOPATH/src/gopl.io/ch1/helloworld 目录中。
Imports
每个包都由其导入路径标唯一标识,包名要求和导入路径的最后一部分相同,例如 gopl.io/ch2/tempconv 导入路径的包名是 tempconv。不同导入路径的包名可能冲突,可以在导入时指定别名来避免冲突。
Package Initialization
包初始化首先会按照声明顺序初始化包级变量,如果包中有多个 .go 文件,go 工具会对按照文件名对文件进行排序,然后调用编译器,文件按照传入编译器的顺序进行初始化。如果变量之间存在依赖关系,则会优先按照依赖关系初始化。
1 | var a = b + c // a initialized third, to 3 |
可以使用 init 函数来初始化包级变量,每个文件都可以包含任意数量的 init 函数,按照声明顺序执行。包按照导入顺序依次初始化,如果包之间存在依赖关系,则会优先按照依赖关系初始化。main 包最后被初始化,从而保证 main 函数开始之前所有包都完成初始化。
1 | // pc[i] is the population count of i. |
1 | // Go 1.6, 2.67GHz Xeon |
Scope
区分作用域(Scope)和生命周期(lifetime),声明的作用域是指程序文本中的一个区域,是编译时的属性。而变量的生命周期是指程序执行期间,其他部分可以引用该变量的时间范围,是运行时的属性。
语法块(syntactic block)是指由花括号包围的语句块,词法块(lexical block)是对语法块概念的泛化,以涵盖未明确使用花括号包围的其它声明组合。整个源代码也是词法块,被称为宇宙块(universe block)。程序可以包含多个同名的声明,只要声明在不同词法块中。当编译器遇到对某个名称的引用,它会从最内层的词法块开始向外找,直到宇宙块为止。
1 | if x := f(); x == 0 { |
Basic Data Types
Go 语言的类型分为四类:基本类型、聚合类型、引用类型和接口类型。基本类型包括数值类型、字符串和布尔类型,聚合类型包括数组和结构体,引用类型包括指针、切片、哈希表、函数和通道。
Integers
数值类型包括整数、浮点数和复数。Go 提供有符号和无符号整数运算,它们分别有四种不同大小的类型,int8, int16, int32, int64 和 uint8, uint16, uint32, uint64。还有 int、uint 和 uintptr 类型,通常为 32 位或 64 位,具体位数由编译器决定。
rune 和 int32 等价,通常用于表示 Unicode 码点。byte 和 uint8 等价,通常用于表示字节数据。在 Go 语言中,% 运算符得到的余数符号总是和被除数相同。没有 ~x 按位取反,而是使用 ^x 执行按位取反。对于有符号数而言,>> 会使用符号位填充。
Floating-Point Numbers
浮点类型有 float32 和 float64 两种,遵循 IEEE 754 标准。32 位浮点数的小数精度大约是 6 位,64 位浮点数的精度大约是 15 位。
1 | var z float64 |
Complex Numbers
有两种复数类型 complex64 和 complex128,它们的元素分别是 float32 和 float64 类型。可以使用内置函数 complex、real 和 imag 处理复数,可以直接使用 i 来声明复数的虚部。
1 | var x complex128 = complex(1, 2) // 1+2i |
Strings
字符串是不可变的字节序列,内置函数 len 返回字符串的字节数量,而不是字符数量,索引操作 s[i] 获取字符串 s 的第 i 个字节。字符串的第 i 个字节不一定就是第 i 个字符,因为非 ASCII 码点的 UTF-8 编码需要多个字节。使用 s[i:j] 可以获取子字符串,该子字符串是一个新的字符串,不过和原串共享底层字节数组。由于可以共享底层内存,所以字符串的复制和子串操作的开销很低。
1 | s := "hello, world" |
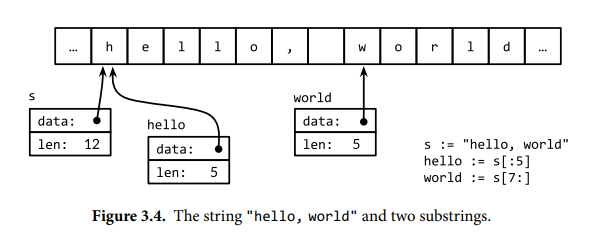
可以在字符串中插入转义序列,特别地,有十六进制转义 \xhh 和八进制转义 \ooo,其中 hh 和 ooo 表示十六进制和八进制数字,八进制数不超过 \377 对应十进制 255。原始字符串字面量(raw string literal)使用的是反引号而不是单引号,输出时不会处理原始字符串字面量中的转义序列。 例外情况是,当原始字符串字面量跨多行编写时,会删除回车符 \r,从而使字符串在所有平台上保持一致。
1 | const GoUsage = `Go is a tool for managing Go source code. |
Unicode
Unicode 是字符编码标准,每个字符对应一个 Unicode 码点,在 Go 中使用 rune 表示(int32 的同义词),即使用 UTF-32 编码方式定长存储 Unicode 码点,但是这样空间开销较大。
UTF-8
UTF-8 变长编码(由 Go 语言开发者发明)使用 1 到 4 字节表示 rune,第一个字节的高位指示当前 rune 使用多少字节表示。变长编码无法直接通过索引访问字符串中的第 n 个字符,但这种编码方式空间有诸多优点。空间占用小,和 ASCII 兼容,自同步(可以通过后退不超过 3 个字节找到字符的开头),从左向右解码不会有歧义。任何字符的编码都不是其他一个或多个字符编码的子串,因此可以通过查找字节来查找字符,而无需担心前面的上下文。字典序和 Unicode 码点顺序相同,不存在嵌入的 NUL 字节(零字节),对于使用 NUL 终止字符串的语言来说非常方便。

Go 的源文件始终使用 UTF-8 编码方式,UTF-8 是 Go 程序处理文本字符串的首选编码方式。可以在字符串中使用 \uhhhh 表示 16 位码点,使用 \Uhhhhhhhh 表示 32 位码点,其中 h 是十六进制数字,每种形式都表示码点的 UTF-8 编码。例如,以下字符串字面量都表示相同的 6 字节字符串。
1 | "世界" |
rune 字面量中也可以使用 Unicode 转义字符,下面三种字面量是等价的。对于值小于 256 的 rune 可以使用单个十六进制转义字符表示,例如 '\x41' 表示 'A'。但是更大的值必须使用 \u 或 \U 转义,'\xe4\xb8\x96' 不是合法的 rune 字面量,即使这三个字节是单个码点的 UTF-8 编码。
1 | '世' '\u4e16' '\U00004e16' |
由于 UTF-8 的特性,许多字符串操作都无需解码。可以使用以下方法检验一个字符串是否是另一个字符串的前缀。
1 | func HasPrefix(s, prefix string) bool { |
字符串 s 占用 13 个字节,包含 9 个码点/字符/rune,要处理字符可以使用 UTF-8 解码器 DecodeRuneInString。不过 Go 的 range 循环在应用于字符串时会自动进行 UTF-8 解码。
1 | s := "Hello, 世界" |

如果 UTF-8 解码遇到非法字节,则会生成特殊的 Unicode 替换字符 \uFFFD,显示为白色问号周围环绕黑色六边形或菱形图案。将 UTF-8 编码的字符串转换为 []rune 之后,会得到 Unicode 码点序列,反之亦然。将整数转换为字符串会将其解释为单个 rune 值,然后将其转换为 UTF-8 表示形式,如果对应的 rune 是无效的,则会使用替换字符。
1 | // "program" in Japanese katakana |
Strings and Byte Slices
字符串 s 可以使用 []byte(s) 转换为字节切片,然后使用 string(b) 转换回来。两个操作通常都会进行复制操作,以确保 b 的可变性和 s2 的不可变性。bytes 包提供 Buffer 类型,类似 Java 中的 StringBuilder,该类型无需初始化,其零值可以直接使用,因为之后调用的方法中会判断底层切片 buf 是否为 nil,然后为其分配内存。
1 | s := "abc" |
Conversions between Strings and Numbers
1 | x := 123 |
Constants
const 常量的底层类型必须是基本类型(和 Java 中的 final 很不一样)。当常量作为一个组声明时,除该组的第一个元素外,剩余元素的右侧表达式可以省略,此时默认会使用之前元素的表达式。
1 | const ( |
The Constant Generator iota
可以使用常量生成器 iota 创建枚举常量组,iota 的值从 0 开始,每次递增 1。
1 | type Flags uint |
Untyped Constants
没有指定类型的常量是无类型(untyped)常量,编译器会以比基本类型更高的数值精度来表示无类型常量,并且在其上执行高精度运算而不是机器运算(受限于 CPU 的位数),至少可以假设其具有 256 位精度。例如 ZiB 和 YiB 无法存储在任何整型变量中,但是可以在下面的表达式中使用。有六种无类型常量:untyped boolean、untyped integer、untyped rune、untyped floating-point、untyped complex 和 untyped string。
1 | const ( |
浮点型常量 math.Pi 可以在需要浮点或复数的情况下使用,但是如果为其指定类型 float64,则精度会降低,而且在需要使用 float32 或 complex128 类型的值时需要显式类型转换。
1 | var x float32 = math.Pi |
只有常量可以不指定类型,当将无类型常量赋值给变量时,该常量会隐式转换为变量的类型。
1 | var f float64 = 3 + 0i // untyped complex -> float64 |
无论隐式还是显式转换,在转换时目标类型必须能够表示原始值,对于实数和复数的浮点数,允许四舍五入。
1 | const ( |
在未显式指定类型的变量声明中,无类型常量的特性会决定变量的默认类型。无类型整型默认转换为 int 类型,无类型浮点数和复数默认转换为 float64 和 complex128。如果要使用其他类型,需要显示类型转换,或者在变量声明中指定类型。在将无类型常量转换为接口值时,默认值非常重要,因为它们会决定接口的动态类型。
1 | i := 0 // untyped integer; implicit int(0) |
1 | fmt.Printf("%T\n", 0) // "int" |
Composite Types
Arrays
数组元素默认初始化为元素类型的零值,可以使用数组字面量(array literal)来初始化数组。在数组字面量中,如果使用省略号 ... 代替数组长度,则数组长度就是列表中元素的数量。数组大小属于类型的一部分,[3]int 和 [4]int 是不同的类型。大小必须是一个常量表达式,在编译时能够确定值。
1 | var a [3]int // array of 3 integers |
1 | var q [3]int = [3]int{1, 2, 3} |
1 | q := [...]int{1, 2, 3} |
除指定值列表外,还可以指定索引和值构成的列表,索引可以按任意顺序排列,不需要列出所有索引,未指定值的索引默认取零值。下面的数组 r 包含 100 个元素,其中最后一个元素的值为 -1。如果数组元素是可比较的,那么相同数组类型之间也可以相互比较,只有当所有对应元素都相等时,两个数组才相等。
1 | r := [...]int{99: -1} |
将数组作为参数传递时,传递的是数组的副本,如果函数想要修改原数组,需要传递指向数组的指针。
1 | func zero(ptr *[32]byte) { |
Slices
切片是可变长的序列,由指针、长度和容量组成。指针指向该切片能够访问的底层数组的第一个元素,该元素不一定是底层数组的第一个元素。长度是切片包含的元素数量,容量是切片起始位置到底层数组末尾之间的元素数量,长度不会超过容量。多个切片可以共享相同的底层数组。
1 | months := [...]string{1: "January", /* ... */, 12: "December"} |
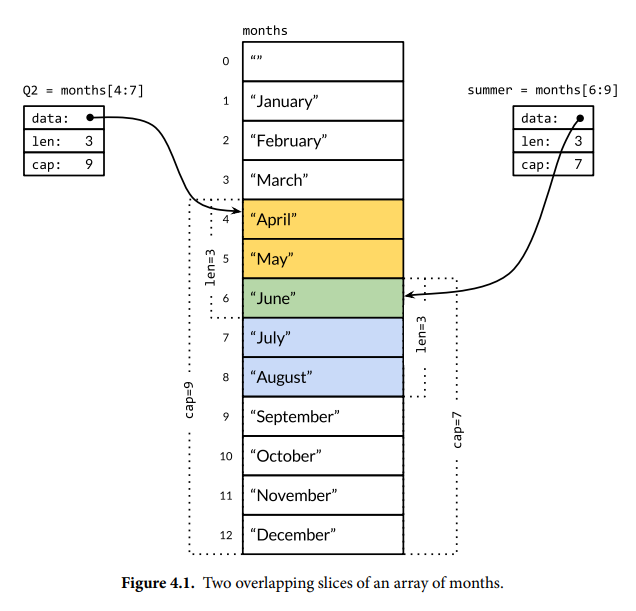
超出切片容量 cap(s) 会导致 panic,超出长度 len(s) 会扩展切片长度。由于切片包含指向底层数组的指针,所以将其作为参数传递不会复制数组元素,参数和切片共享底层数组。
1 | fmt.Println(summer[:20]) // panic: out of range |
切片字面量和数组字面量类似,只是未给出大小,它会先创建具有正确大小的数组,然后将该数组作为切片的底层数组。
1 | s := []int{0, 1, 2, 3, 4, 5} |
和数组不同,切片无法进行比较,不能使用 == 判断两个切片是否相等。标准库提供对 []byte 切片的比较函数 bytes.Equal,对于其他类型的切片,需要自己实现比较逻辑。例外情况是,切片可以和 nil 进行比较。
1 | if summer == nil { /* ... */ } |
切片的零值是 nil,nil 切片的长度和容量都是零。不过长度和容量为零的切片不一定是 nil 切片,例如 []int{} 或 make([]int, 3)[3:]。除和 nil 进行相等性比较之外,nil 切片和任何其他长度为零的切片具有相同的行为。
1 | var s []int // len(s) == 0, s == nil |
内置函数 make 用于创建切片,如果省略容量参数,则容量默认和长度相等。内部实现上,make 会创建未命名的数组变量,然后返回该数组的一个切片,该数组只能通过切片访问。
1 | make([]T, len) |
The append Function
内置函数 append 将元素添加到切片。如果容量足够则扩展切片长度,这会返回一个更大的新切片,和原切片共享底层数组。如果容量不足,则需要创建新数组,将旧数组的元素复制到新数组,此时和原切片的底层数组不同。下面是一个简易实现示例,内置函数 append 可能更加复杂。
1 | func appendInt(x []int, y int) []int { |
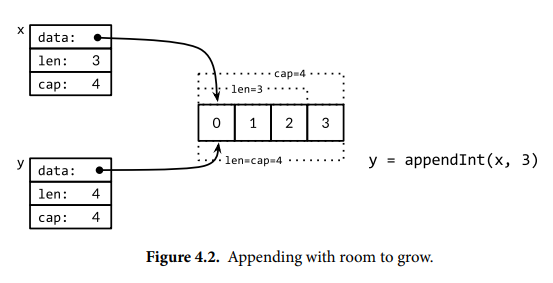
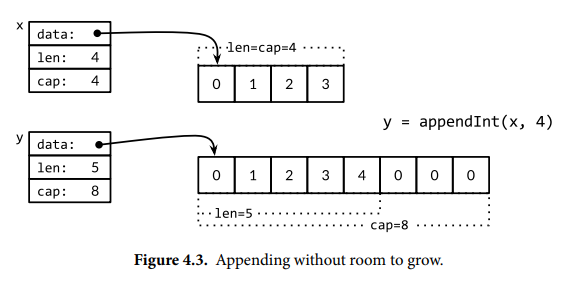
内置的 append 函数允许添加多个元素或切片,省略号 ...int 表示函数具有可变参数,在切片之后添加省略号表示将其展开为参数列表。
1 | var x []int |
Maps
map 是对哈希表的引用,表示为 map[K]V,其中 K 和 V 分别是键值的类型。键类型必须能够使用 == 比较,不建议使用浮点数作为键,因为浮点数可以是 NaN。可以使用内置函数 make 或哈希表字面量(map literal)创建 map,使用内置函数 delete 删除键。如果键不在哈希表中,则会返回值类型对应的零值。
1 | ages := map[string]int{ |
map 元素不是变量,无法获取其地址,原因之一是扩容会导致地址失效。
1 | _ = &ages["bob"] // compile error: cannot take address of map element |
可以使用基于范围的 for 循环遍历哈希表。map 的迭代顺序不是确定性的,实际实现为随机顺序,如果要按照顺序遍历,需要对键进行排序。由于已知 names 的最终大小,所以预分配指定容量的数组会更高效。
1 | names := make([]string, 0, len(ages)) |
map 类型的零值是 nil,表示没有引用哈希表。对 nil 映射执行 []、delete、len 和 range 都是安全的,其行为和空映射 map[string]int{} 类似。但是不允许向其中存储数据,会导致程序崩溃。
1 | var ages map[string]int |
可以使用以下形式判断 map 中是否存在指定的键,以和默认零值区分开来。和切片类似,map 之间不能相互比较,只允许其和 nil 进行比较。如果想要将切片作为键,由于切片是不可比较的,所以可以将切片转换为字符串。
1 | if age, ok := ages["bob"]; !ok { /* ... */ } |
Structs
使用 type xxx struct 形式声明结构体,指向结构体的指针可以直接通过 . 访问其字段(不像 C++ 需要使用 ->),该写法等价于显式解引用之后再使用 .。字段通常一行写一个,不过相同类型的连续字段可以合并书写。字段顺序对于类型标识至关重要,不同字段顺序定义得到的是不同的类型。如果字段名称以大写开头,则该字段会被导出。
1 | type Employee struct { |
1 | var employeeOfTheMonth *Employee = &dilbert |
具有名称 S 的结构体不能声明类型为 S 的字段,即不能包含自身类型的字段,但是可以包含指向自身类型的指针。结构体的零值由其每个字段的零值组合而成。没有字段的结构体 struct{} 被称为空结构体,其大小为零,可以用作 map[string]struct{}{} 表示集合类型。
Struct Literals
可以使用结构体字面量(struct literal)初始化结构体,如果不指定类型,需要按照字段声明顺序,给所有字段指定初始值。如果指定类型,则可以随意指定某些字段的初始值,剩余字段默认初始化为零值。结构体作为参数传递使用的是值传递,可以仅传递指针来提高效率。两种形式不能在相同字面量中混合使用。
Comparing Structs
如果结构体的所有字段都是可比较的,那么该结构体就是可比较的,因此可以使用 == 或 != 进行比较。和其他可比较类型类似,可比较的结构体也可以作为 map 的键。
Struct Embedding and Anonymous Fields
可以使用结构体嵌入(struct embedding)将一个结构体作为另一个结构体的匿名字段,从而允许将形如 x.d.e.f 的字段链简化为 x.f。Go 中使用组合而不是继承复用代码,结构体嵌入可以简化组合产生的过长字段链。由于匿名字段实际上有隐含的名称,所有不能有两个相同类型的匿名字段,因为它们会相互冲突。
1 | type Point struct { |
JSON
将 Go 数据结构序列化为 JSON 字符串,可以使用 json.Marshal 函数。序列化会将 Go 结构体字段名称用作 JSON 对象的字段名称,只有导出的字段才会被序列化。通过定义适当的数据结构,在反序列化时可以获取指定的数据,其余数据将被忽略。可以使用字段标签(field tags)替换 JSON 中默认的字段名称,使用 key:"value" 形式声明字段标签。字段标签通常用于将 Go 字段的驼峰命名转换为 JSON 字段的下划线命名,可以使用 omitempty 表示字段为零值或者为空时不生成对应的 JSON 输出。
1 | type Movie struct { |
Functions
Function Declarations
函数声明包含名称、参数列表、返回值列表以及函数体。如果函数值返回单个未命名返回值或者没有返回值,则可以省略返回值列表的括号。可以给返回值命名,此时默认会为每个名称声明对应的局部变量,初始化为其类型的零值。有返回值列表的函数必须以 return 语句结束,除非程序不会到达函数末尾。
1 | func name(parameter-list) (result-list) { |
相同类型的参数可以分为一组,仅编写一次类型。空标识 _ 表示参数未被使用。函数的类型有时被称为其签名(signature),如果两个函数具有相同的参数类型和返回值类型,那么它们就具有相同的签名。参数和返回值的名称不会影响签名,签名也不受分组形式声明的影响。
1 | func add(x int, y int) int { return x + y } |
参数总是值传递的,函数会接受参数的副本,对副本进行修改不会影响调用者。当参数是引用类型时,函数可以修改该参数间接引用的变量。如果发现某个函数没有函数体,则说明该函数是使用其他语言编写的。
1 | func Sin(x float64) float64 // implemented in assembly language |
Recursion
许多编程语言使用固定大小的函数栈,通常为 64KB 到 2MB之间。固定大小的函数栈会限制递归调用的深度,需要小心避免栈溢出。Go 使用可变大小的栈,初始较小然后根据需要增大,直至达到大约 1GB 的上限。
Multiple Return Values
Go 语言的垃圾回收机制会回收未使用的内存,但它不会自动释放未使用的操作系统资源,比如打开的文件和网络连接,这些资源应当显式的关闭。具有命名返回值的函数可以省略 return 语句的操作数,这被称为裸返回(bare return)。
1 | func Size(rect image.Rectangle) (width, height int) |
Errors
对于失败(failure)是预期行为的函数,通常会有额外的返回值。如果失败的原因只有一个,那么额外返回布尔类型,否则应该返回 error 类型。内置类型 error 是接口类型,为 nil 时表示成功,反之则表示失败。和其他使用异常机制的语言不同,Go 语言使用 panic 表示非预期的错误,预期错误则使用 if 和 return 控制流机制实现错误处理。
Error-Handling Strategies
当函数调用出现错误时,调用方有责任检查并采取相应措施。最常见的处理方式是传播错误,也可以为错误添加额外信息。因为错误通常是链式的,所以消息字符串不应该大小,也不应该使用换行符。通常函数 f(x) 负责报告所执行的操作 f 以及与错误相关的参数 x,而调用者负责补充 f(x) 没有的其它信息。
1 | resp, err := http.Get(url) |
另一种错误处理方式是重试,需要设置重试次数和重试前的等待时间。如果无法取得进展,调用者可以打印错误信息并终止程序,但这种处理方式仅用于程序的主要模块中。库函数通常应该将错误信息传递给调用者,除非该错误是 BUG。在某些情况下,可以仅记录错误信息并继续运行。极少数情况下,可以完全忽略某个错误。
End of File (EOF)
文件结束条件会产生 io.EOF 错误,需要特殊处理该错误。
1 | in := bufio.NewReader(os.Stdin) |
Function Values
在 Go 语言中,函数是一等公民(first-class values),像其他值一样,函数值也有类型,也可以作为参数传递给函数或从函数返回。函数类型的零值是 nil,调用 nil 函数会导致 panic,函数值之间是不可比较的,只能和 nil 比较。
1 | func square(n int) int { return n * n } |
Anonymous Functions
命名函数只能在包级进行声明,而匿名函数可以在任意表达式中使用。每次调用 squares 都会创建一个局部变量 x,并返回一个类型为 func() int 的匿名函数。此时,匿名函数可以访问和修改外层函数的局部变量 x。这些隐含的变量就是将函数视为引用类型,以及函数值之间无法比较的原因。这类函数值使用闭包(closures)技术实现。就像之前提到的返回局部变量的地址的例子,闭包示例也说明变量的生命周期不是由作用域决定,而是由可达性决定。
1 | // squares returns a function that returns |
当匿名函数需要递归时,必须先声明一个变量,然后将匿名函数赋值给该变量。
1 | visitAll := func(items []string) { |
Caveat: Capturing Iteration Variables
在迭代中使用匿名函数时,需要避免捕获迭代变量的陷阱,正确的做法是声明一个同名的局部变量覆盖迭代变量。
1 | var rmdirs []func() |
Variadic Functions
可变参函数的最后一个参数类型前面使用省略号 ...,表示可以接收任意数量的该类型参数。实际上,调用者会创建一个数组,将参数赋值到其中,然后将数组的切片传递给函数。
1 | func sum(vals ...int) int { |
尽管 ...int 参数的行为类似切片,但是可变参函数的类型和带有切片参数函数的类型并不相同。
1 | func f(...int) {} |
Deferred Function Calls
defer 关键字之后跟函数调用,表示延迟执行该调用。函数和参数表达式在执行该语句时就会被计算,而实际调用则会推迟到包含该 defer 语句的函数执行完毕时,无论函数是正常/异常结束。可以有任意数量的调用被延迟执行,它们会以执行 defer 语句相反的顺序依次执行(类似栈 LIFO)。
1 | var mu sync.Mutex |
可以在单个 defer 语句中,对函数的入口和出口进行检测。下面的 trace 函数会立即被调用,而其返回的函数在 bigSlowOperation 函数结束时被调用。
1 | func bigSlowOperation() { |
延迟执行的函数在 return 语句更新完返回值变量之后执行,可以在其中修改返回值。
1 | func triple(x int) (result int) { |
Panic
当 Go 运行时检测到严重的错误时,会产生 panic,正常执行会停止,从函数栈顶到 main 函数的所有延迟函数调用会依次执行,然后程序会崩溃并记录日志。可以显示调用内置的 painc 函数。对于函数的前置条件进行确认是良好的做法,但是除非能够提供更详细的错误信息或更早地检测到错误,否则没有必要去确认在运行时会自动检查的条件。
1 | func Reset(x *Buffer) { |
Recover
如果在延迟函数中调用内置的 recover 函数,且包含该 defer 语句的函数发生 panic,那么 recover 会终止当前的 panic 状态并返回 panic 的值。发生 panic 的函数不会继续执行,而是直接返回。在没有发生 panic 时调用 recover 函数不会有任何效果,仅仅返回 nil。
1 | func Parse(input string) (s *Syntax, err error) { |
Methods
Method Declarations
方法声明就是在函数名之前添加额外的参数,该参数将函数和该参数的类型绑定。额外的参数 p 被称作该方法的接收者(receiver),在 Go 语言中,没有使用 this 或 self 表示接收者,而是像对待普通参数一样选择接收者的名称,通常使用类型的首字母作为其名称。以下两个函数声明不会相互冲突,一个是包级函数,另一个是 Point 类型的方法。
在 Go 语言中,字段和方法不能同名(和 Java 不同)。和其他面向对象语言不同,Go 中可以为大多数类型定义方法,而不仅仅是结构体类型。例外情况是:① 不能直接为基本类型定义方法,而必须使用 type 创建命名类型;② 不能为指针和接口类型定义方法,但是接收者可以是指向非指针类型的指针。另外,类型和方法必须定义在相同的包中。
1 | type Point struct{ X, Y float64 } |
Methods with a Pointer Receiver
如果方法使用 (p Point) 声明,则和普通参数一样会复制该变量,如果想要在方法中修改相关变量,则应该使用 (p *Point) 指针类型接收变量的地址。在调用时也需要通过指针调用该方法,不过语法上允许直接通过 Point 变量而不是 *Point 调用 ScaleBy 方法,编译器会对其隐式地执行 & 取址操作。对于临时值由于还没有为其分配地址,所以不能使用简写形式。同样可以通过 *Point 变量调用 Distance 方法,编译器会隐式地执行 * 解引用操作。
1 | func (p *Point) ScaleBy(factor float64) { |
1 | Point{1, 2}.ScaleBy(2) // compile error: can't take address of Point literal |
Nil Is a Valid Receiver Value
正如函数允许将 nil 指针作为参数,接收者也可以为 nil,当 nil 是该类型有意义的零值时。
1 | // An IntList is a linked list of integers. |
Composing Types by Struct Embedding
结构体嵌入会将内部组合结构体的方法提升到外部结构体中。这种组合方式和继承不同,两种类型并不是父子关系,不具有多态性。实际上,编译器会生成包装方法,其内部会调用字段的对应方法。
1 | type ColoredPoint struct { |
1 | func (p ColoredPoint) Distance(q Point) float64 { |
Method Values and Expressions
1 | p := Point{1, 2} |
1 | p := Point{1, 2} |
Interfaces
Interface Satisfaction
接口类型是抽象类型,其定义一组方法,只要具体类型有这些方法,就可以被视为该接口的实例(隐式实现接口)。接口类型之间也可以嵌入,使得当前接口具有另一个接口的方法,而不需要显示的全部定义出来。只要具体类型或接口类型有某个接口类型的所有方法,就可以将其赋值给该接口类型。可以将任何值赋值给空接口类型 interface{}。可以使用以下方式,在编译时断言 bytes.Buffer 类型满足 io.Writer 接口。
1 | var any interface{} |
1 | // *bytes.Buffer must satisfy io.Writer |
Interface Values
接口类型的值(interface value)包含两个组成部分,即具体类型以及该类型的值,它们被称为动态类型(dynamic type)和动态值(dynamic value)。动态类型由类型描述符(type descriptor)表示,其提供类型的字段和方法信息。接口的零值,其类型和值的组成部分都被设置为 nil。如果接口的类型部分是 nil,则该接口值就是 nil。
1 | var w io.Writer |
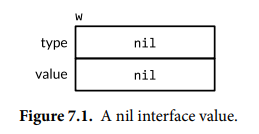
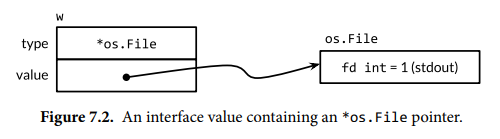
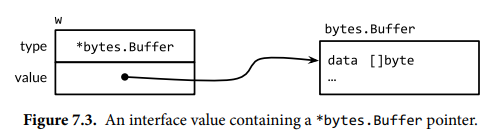
可以使用 == 和 != 比较接口值,如果两个接口值均为 nil,或者它们的动态类型和动态值都相同,则这两个接口值相同。如果两个接口值的动态类型相同,但是它们的动态类型不支持比较操作,则会引发 panic。
1 | var x interface{} = []int{1, 2, 3} |
Caveat: An Interface Containing a Nil Pointer Is Non-Nil
当 debug = false 时,下面的代码会引发 panic,因为接口值的动态类型不是 nil,而动态值是 nil,在调用 (*bytes.Buffer).Write 方法时会出问题。解决方案是,将 buf 声明为 var buf io.Writer,避免将无效值(bytes.Buffer 类型的 nil 指针)赋值给接口类型。
1 | const debug = true |
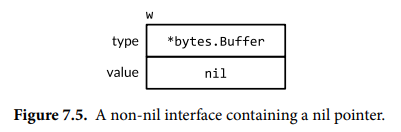
Type Assertions
类型断言(type assertion)是对接口值执行的操作,形如 x.(T),其中 x 是接口类型的表达式,T 是断言类型。如果 T 是具体类型,那么类型断言会检查 x 的动态类型是否和 T 相同,如果相同则返回 x 的动态值,否则引发 panic。
1 | var w io.Writer |
如果 T 是接口类型,那么类型断言会检查 x 的动态类型是否满足 T,如果满足则返回类型为 T 的接口值,该接口值和 x 具有相同的动态类型和动态值。不论 T 是什么类型,如果 x 是 nil,则断言会失败。
1 | var w io.Writer |
如果使用以下类型断言方式,则断言失败不会引发 panic,而是额外返回 false。
1 | var w io.Writer = os.Stdout |
Type Switches
1 | func sqlQuote(x interface{}) string { |