分布式系统的挑战
不可靠的网络
网络分区故障,指网络的一部分由于网络故障而与其他部分断开,其实可以直接称为网络故障。作者推荐,可以通过故意触发网络问题,来测试系统的反应。
在分布式系统中,需要设置响应的超时时间,从而判断节点是否失效。如果时间设置得太长,则需要等待更长的时间。如果时间设置得太短,可能节点只是负载过高而响应缓慢,此时判断节点失效并将负载转移到其他节点会进一步增加系统负载,从而可能导致失效扩散(还可能会导致其他异常)。比较好的做法是,持续测量响应时间及其变化,然后根据测量结果自动调整超时时间。
从广义上讲,网络延迟的波动可以视为资源动态分配的结果。传统的电话网络(非 VoIP)使用电路交换技术,为每个通话分配一条固定带宽的通信链路,网络的延迟是确定的;而互联网使用分组交换技术,所有用户共享网络带宽,用户之间的数据存在排队的情况,该方法可以增加带宽的利用率,但是理论上的延迟是无限大的。
不可靠的时钟
网络上的每台机器都有独立的时钟硬件设备,通常是石英晶体振荡器,用于维护机器的本地时间,该时间可能与其他机器上的时间不同。通常使用网络时间协议(Network Time Protocol,NTP)来同步机器之间的时间,该协议根据一组专门的时间服务器来调整本地时间(调整石英的振动频率),时间服务器则从精确度更高的时间源(例如 GPS 接收器)获取高精度时间。
墙上时钟和单调时钟
现代计算机内部至少有两种时钟:墙上时钟和单调时钟。
墙上时钟
墙上时钟根据某个日期返回当前的日期与时间,例如 Linux 的 clock_gettime(CLOCK_REALTIME) 和 Java 的 System.currentTimeMillis() 会返回自 1970 年 1月 1 日(UTC)以来的秒数和毫秒数,不含润秒。有些系统则使用其他日期作为参考点。
墙上时钟需要使用 NTP 进行同步,但是存在很多问题。特别是,如果本地时钟远远快于 NTP 服务器,则同步之后会发生时间倒退的现象,以及墙上时钟经常忽略润秒,导致其不太适合用于测量时间间隔。
单调时钟
单调时钟不需要和 NTP 服务器时钟进行同步,适合测量时间间隔。例如 Linux 的 clock_gettime(CLOCK_MONOTONIC) 和 Java 中的 System.nanoTime() 返回的都是单调时钟。单调时钟的单个值没有任何意义,它可能是电脑启动后经过的纳秒数或者其他含义,不同节点上的单调时钟没有相同的基准,不能相互比较。
时钟同步和准确性
硬件时钟和 NTP 服务器可能会出现各种问题,例如:计算机中的石英钟存在漂移现象(运行速度会加快或减慢,取决于机器的温度);如果本地时钟和 NTP 服务器时钟相差太大,应用程序可能会看到时间倒退或跳跃的现象;同步的准确性受限于网络延迟,以及 NTP 服务器是否正常工作;各种其他情况,包括下面提到的润秒。
润秒(Leap second)就是对协调世界时(Coordinated Universal Time,UTC)增加或减少 1 秒,以使协调世界时和世界时(UT,通常指 UT1)之间的差异不超过 0.9 秒。2022 年 11 月,国际计量大会决定在 2035 年之前取消润秒。润秒曾经使许多大型系统崩溃,根本原因是许多系统没有正确适配润秒,软件存在 BUG 从而引发各种问题。可以看下 The Inside Story of the Extra Second That Crashed the Web 这篇文章,讲述了现实中发生过的问题。Google 处理润秒方式是,在一天内逐步调整时间,而不是在一天结束时直接改变 1 秒。PS:一个显示各个时钟目前时间的网站。
如果投入大量资源,可以达到非常高的时钟精度,例如交易系统的时钟就要求很小的时钟误差。高精度的时钟可以使用 GPS 接收器,精确时间协议(PTP)并辅以细致的部署和监测来实现。
依赖同步的时钟
如果应用需要精确同步的时钟,最好仔细监控所有节点上的时钟偏差。如果某个节点的时钟漂移超出上限,则将其视为失效节点并从集群中移除。这样监控的目的是确保在造成重大影响(例如隐式的数据丢失)之前尽早发现并处理问题。
时间戳和事件顺序
在无主复制的检测并发写中提到过,最后写入者获胜(LWW)冲突解决策略由于时钟偏差,可能会覆盖非并发写入。
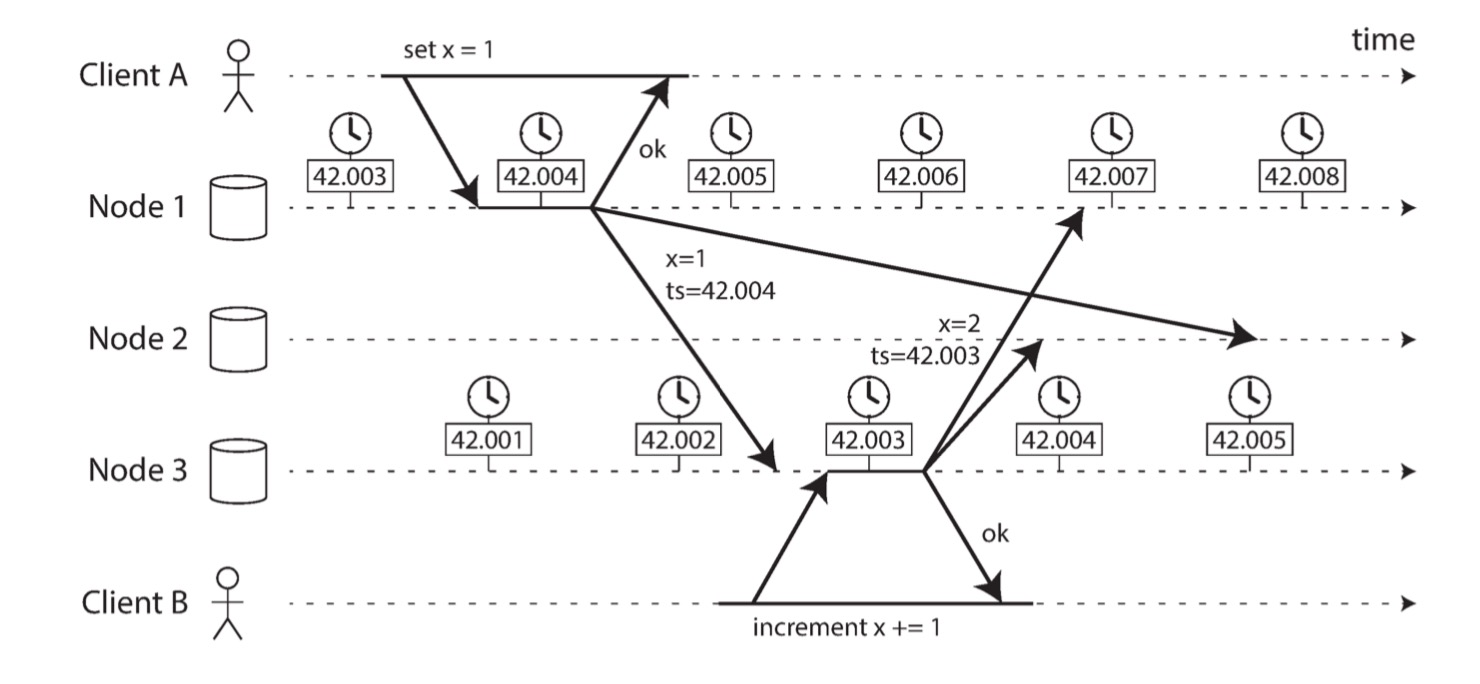
在上述例子中,时钟同步机制稳定工作,节点 1 和节点 3 之间的时钟偏差小于 3ms,但是时间戳却不能正确排序事件,从而导致客户端 B 的增量操作被覆盖。解决方案就是之前提到过的,使用版本向量技术跟踪因果关系。PS:因果关系其实就是非并发写操作的前后关系,版本向量不仅可以跟踪因果关系,还可以判断写操作是否并发。
时钟的置信区间
或许墙上时钟会返回微秒甚至纳秒级别的信息,但是这种精度的测量值其实并不可信,因为存在石英漂移和网络延迟等不确定性因素。所以,我们不应该将时钟读数视为一个精确的时间点,而应该视为带有置信区间的时间范围。例如,系统可能有 95% 的置信度认为目前时间介于 10.3~10.5 秒之间。
可以根据具体的时间源来推算出时钟误差的上限。如果节点上直接装有 GPS 接收器或原子(铯)时钟,那它的误差范围通常可查询制造商的手册。如果节点是从服务器获取时间,则不确定性取决于上次同步以来的石英漂移范围,加上 NTP 服务器的不确定性,再加上节点和服务器之间的往返时间。
但是,大多数系统并不提供这种误差查询接口,通常只会返回某个确定的时间,而没有任何误差信息。Google Spanner 中的 TrueTime API 提供误差查询,它会返回时间的上下界。
全局快照的同步时钟
该节主要是讲如何在分布式场景下,生成全局单调递增的事务 ID,有点不明白这个标题是什么意思。如果是单节点数据库,使用一个计数器就可以实现正确的事务 ID。但是,如果是多节点数据库,则更加复杂并且开销更大。
Twitter 使用雪花(Snowflake)算法来生成近似单调递增的唯一 ID。如果节点之间的墙上时钟完全同步,则也可以将其作为事务 ID,但是实际上是不可能的。Google Spanner 使用 TrueTime API 返回的时钟置信区间作为事务 ID,如果两个置信区间没有重叠,则可以知道两个事务的先后顺序。
进程暂停
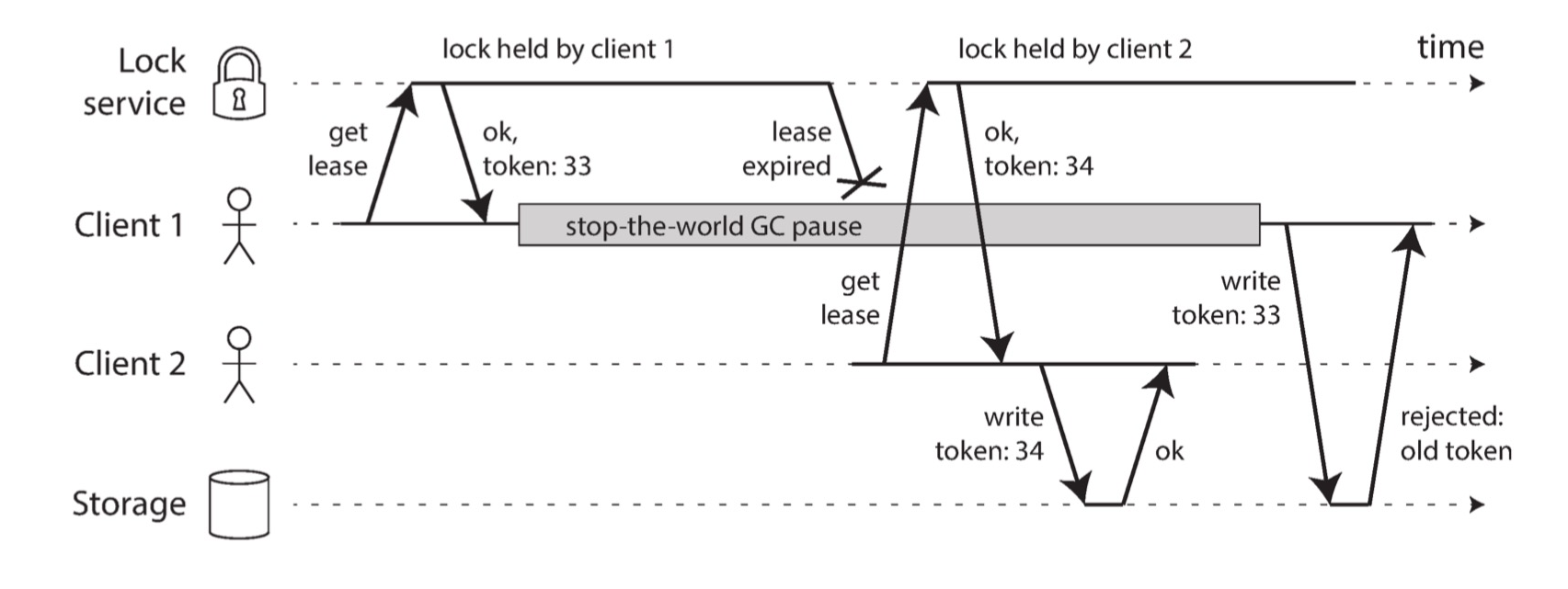
在使用主从复制的数据库中,只有主节点可以接受写入,如果主节点失效则需要将某个从节点提升为主节点。判断节点是否失效可以使用租约来实现:如果某个节点持有租约,那么它就是主节点;如果租约过期,则该节点失效。我们可以使用单调时钟来判断租约是否过期,但是可能由于垃圾收集、上下文切换或磁盘 I/O 等原因导致进程暂停,从而使得暂停之前判断租约没有过期,暂停之后发送请求时租约已经过期。
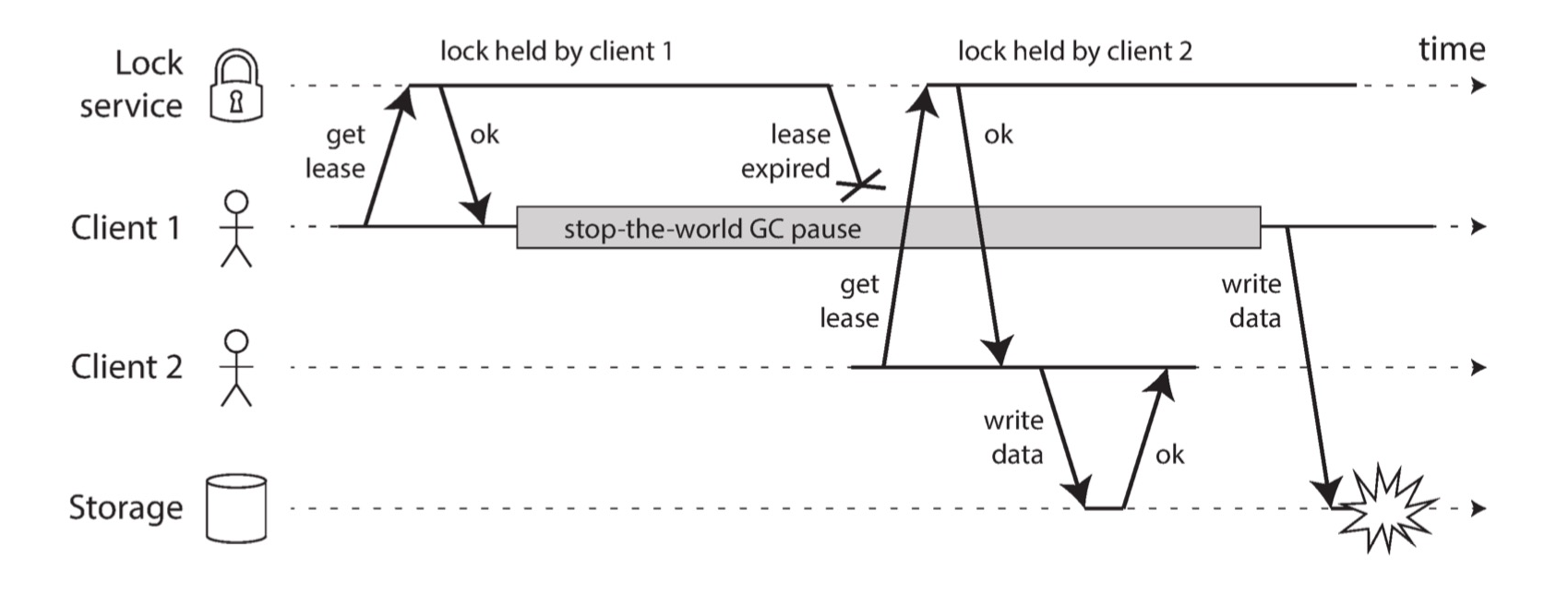
上图是 HBase 曾经遇到的问题,不正确的分布式锁实现,导致未持有锁的客户端修改数据。解决方案是,锁服务为每个锁维护一个单调递增的 fencing 令牌(实际上就是版本号),在锁服务授予客户端租约和客户端向存储服务发送写请求时会包含该令牌,存储服务也会维护数据最后一次修改对应的令牌。如果存储服务收到的写请求包含旧令牌,则会拒绝该请求。如果使用 ZooKeeper 作为锁服务,则事务标识 zxid 或节点版本 cversion 可以充当 fencing 令牌。