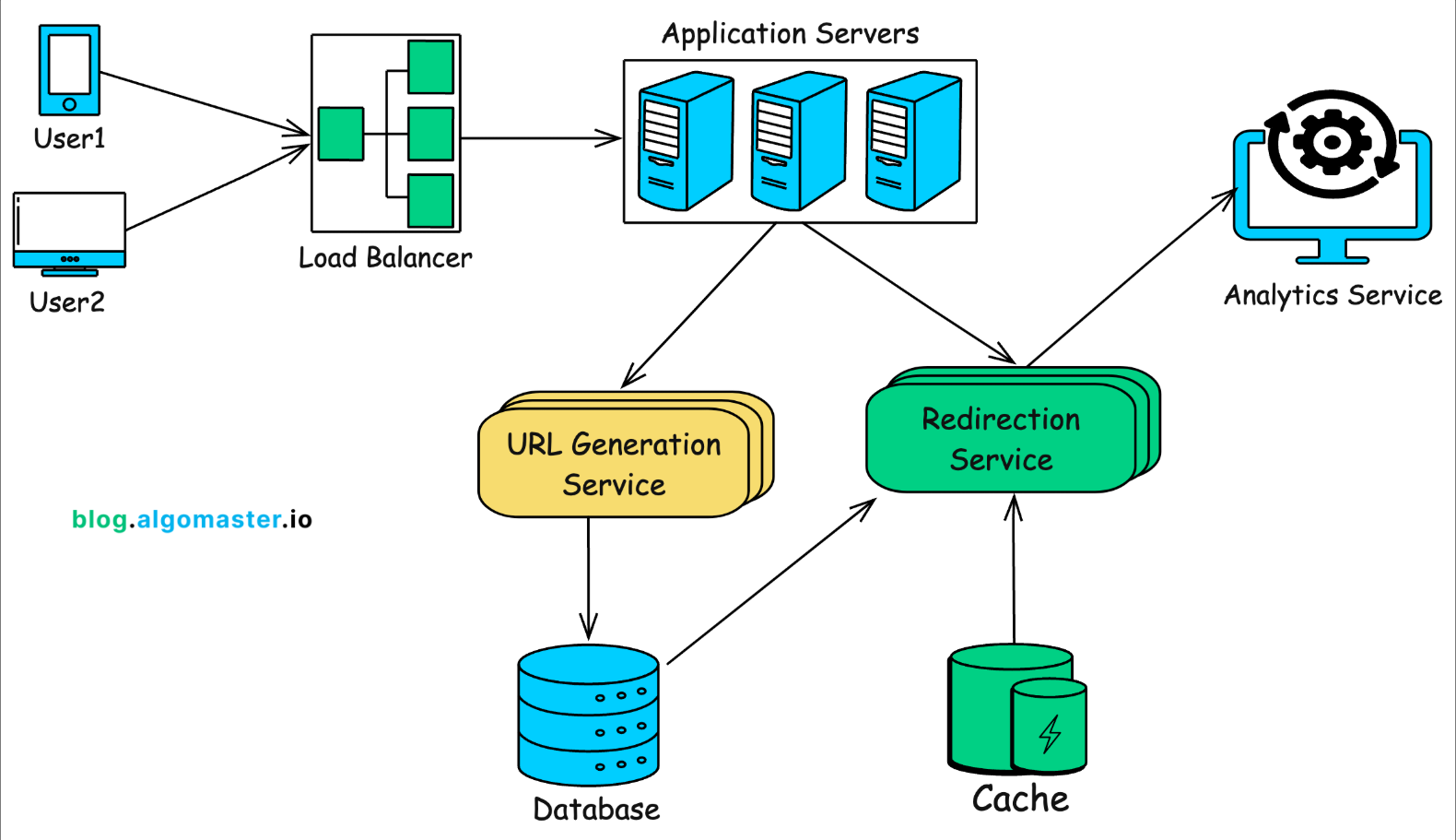
参考 GitHub Awesome System Design。
我的想法
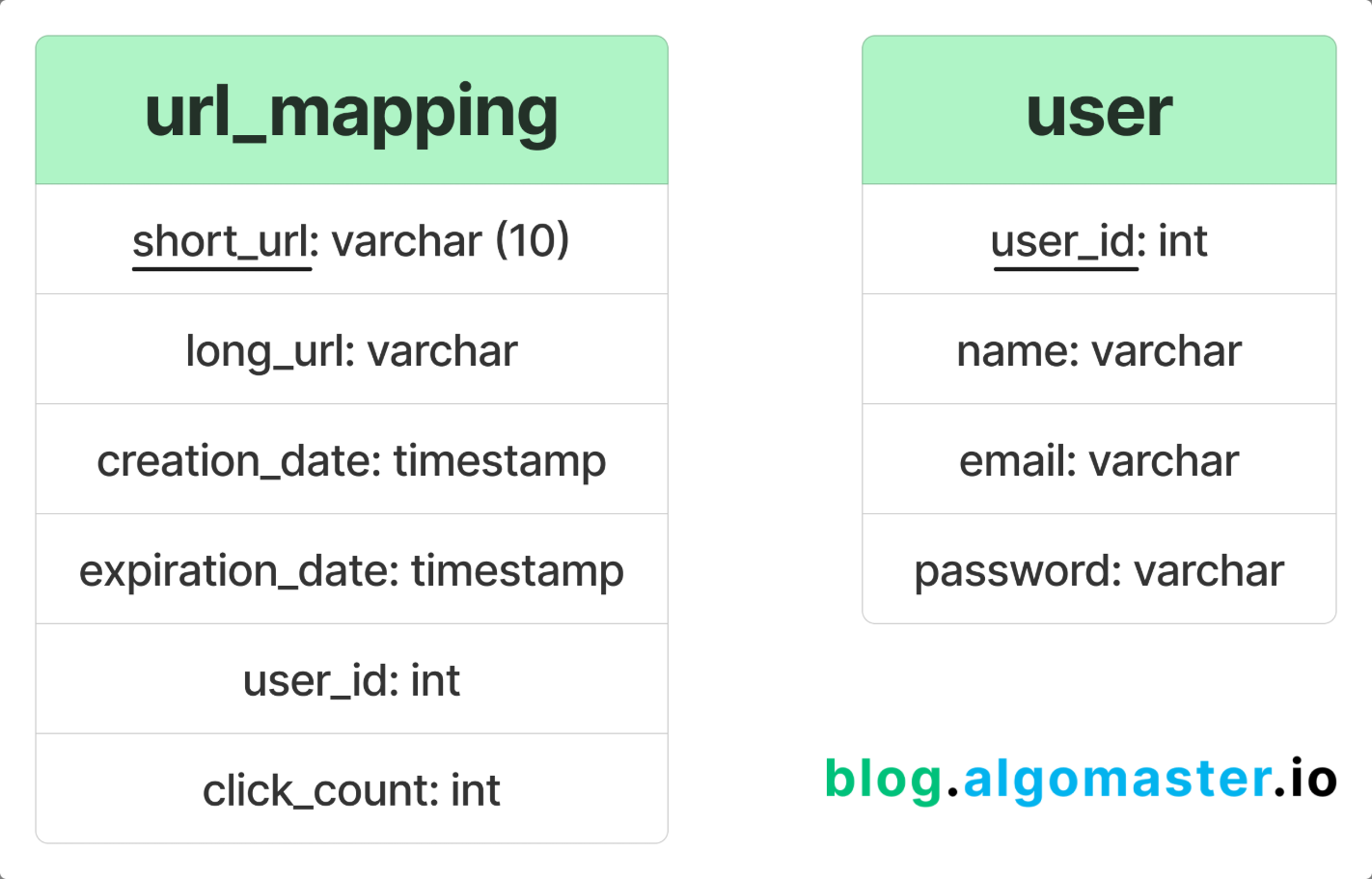
核心功能就是长链转短链,可以从使用算法和存储方式两个方面思考。算法首先想到的是哈希函数,可以将长链转为一个短链整数(需要处理哈希冲突),然后使用 Base62 编码为包含 [0-9a-zA-z] 的短链字符串。存储时可以存储长链和短链整数/字符串,不同存储格式主要是时间和空间的权衡,然后需要分别在两个字段上建立唯一/前缀索引来加速查询。
实际上可以将数据库的主键 ID 作为短链整数,这样空间占用更小,也不存在哈希冲突。查询短链到长链的映射可以直接利用主键索引,只需给长链建立索引来加速反向查询。虽然每次查询都要将短链整数编码为短链字符串,不过时间开销不算大,长度为 7 的字符串就可以表示 \(62^7\approx3\times 10^{12}\) 个不同的短链,而且可以使用缓存提升查询性能。
文章内容
需求分析可以分为功能性需求和非功能性需求,功能性需求主要是业务需求,非功能性需求包括高性能、高可用、可扩展性和安全性。然后可以假设流量特征来估算系统的吞吐量、磁盘/内存空间以及带宽需求。流量特征可以从每日缩短 URL 的请求数量、读写比例、峰值流量和平均 URL 长度等方面思考。最后根据估算结果来估计需要的基础设施。
假设每天 100 万个缩短 URL 的请求,读写比例 100 : 1,峰值流量是平均负载的 10 倍,平均 URL 长度为 100 个字符。计算吞吐量,平均写吞吐量 \(\frac{\times 10^{6}}{24\times3600}\approx 12\) WPS,平均读吞吐量 \(100\times 12=1200\) RPS。假设每个 URL 占用 127 字节的存储空间,由短链 7 字节、长链 100 字节、创建时间 8 字节、到期时间 8 字节和点击次数 4 字节组成,那么每年就需要 \(127\times 10^{6}\times 365\approx 46.4\) GB 的磁盘存储空间。假设读取返回的 HTTP 301 重定向大小为 500 字节,每天读取带宽为 \(500\times 10^{6}\times 100= 50\) GB/day,每秒峰值读取带宽为 \(500\times RPS\times 10= 6\) MB/s。
系统负载是读多写少的,假设负载符合二八定律(Pareto principle),即 20% 的 URL 产生 80% 的读取流量。假设每天缓存 20% 的 URL,则需要 \(127\times 10^{6}\times 0.2=25.4\) MB 的内存作为缓存。假设缓存命中率为 90%,则到达数据库的平均请求数量为 \(1200\times0.1=120\) RPS。最后根据以上估算结果,估计使用 4-6 个服务器,每个服务器能够处理 200~300 RPS,10~20 个分布式数据库节点,3~4 个分布式缓存节点。
由于需要存储数十亿条记录,而且数据库操作大多是简单的键值查找,不需要执行复杂的表连接,所以选择使用 DynamoDB 或 Cassandra 等 NoSQL 数据库,因为它们能够高效处理数十亿次简单键值的查找,而且提供高可扩展性和高可用性。
可以对长链使用哈希函数(MD5、SHA-256)得到哈希值,然后取哈希值的前缀转十进制,再使用 Base64 编码得到短链。要处理哈希冲突,可以使用不同的种子重新哈希或者取哈希值的其它位生成短链,也可以将增量后缀附加到短链。另一种生成短链的方式是使用分布式 ID(数据库自增 ID、Redis 生成 ID、雪花算法),从安全性角度思考,增量 ID 是可预测的,有人可以通过使用短链服务推断系统的 URL 总数或者猜测其他用户生成的 URL,混淆(Obfuscation)增量 ID 可以缓解该问题。
额外功能:① 用户自定义短链,需要进行格式校验以及唯一性检查,如果和已有的短链发生冲突,服务器可以返回错误或者建议的替换方案。服务器还可以保留部分短链,以供内部使用。② 设置短链的过期时间,由用户指定或者使用默认的过期时间,可以使用定时任务或者在请求时检测短链是否过期,然后(逻辑)删除过期短链。③ 可以使用消息队列记录短链的访问日志,然后批量处理日志将其聚合存储在数据仓库中,以实现分析服务。
其他问题:① 使用负载均衡、基于范围/哈希的分片、缓存保证可扩展性。② 使用复制、自动故障转移、跨多个地理区域部署服务保证可用性。③ 处理边界条件,例如对于过期短链服务器返回 HTTP 401 状态码,不存在的短链返回 404 状态码,在生成短链时检测冲突。④ 限流防止滥用,输入校验确保用户提供的短链不包含恶意内容,使用 HTTPS 防止窃听和中间人攻击,对异常活动模式进行监控和报警。
遗漏的点
功能性需求没有想到重定向和过期时间的设计,以及允许用户自定义短链、数据分析等额外功能。重定向可以使用 301/302 状态码(永久/临时重定向),临时重定向每次请求都会经过短链服务,从而可以统计短链的使用次数。没有特别思考非功能性需求,基本上是从单服务器的角度思考问题。对哈希函数有点误解,误认为哈希的结果都是整数,像是 MD5、SHA 生成的哈希值都是可以包含字母的。我之前都是默认使用 MySQL + Redis 的组合,没有想到使用其他 NoSQL 数据库。使用哈希函数索引实现长链快速判重,使用布隆过滤器过滤请求。
一些疑问
Q:为什么估计使用 4-6 个服务器,10~20 个分布式数据库节点,3~4 个分布式缓存节点?
Q:文章描述的系统似乎只会检测短链冲突,而没有检测重复的长链?
Q:DynamoDB 和 Cassandra 数据库有什么特点?
我的想法
排行榜主要是按照分数对用户进行排序,功能性需求主要是显示排名和更新排名。像是游戏打完排位会显示排名上升多少,然后排行榜只会显示 TopK 用户,每隔固定时间才更新榜单。像是算法比赛的排行榜会显示所有用户,榜单也是实时更新的。对于 TopK 榜单一般会使用小顶堆来实现,当新分数大于堆顶元素时,就弹出堆顶元素然后将当前元素入堆。
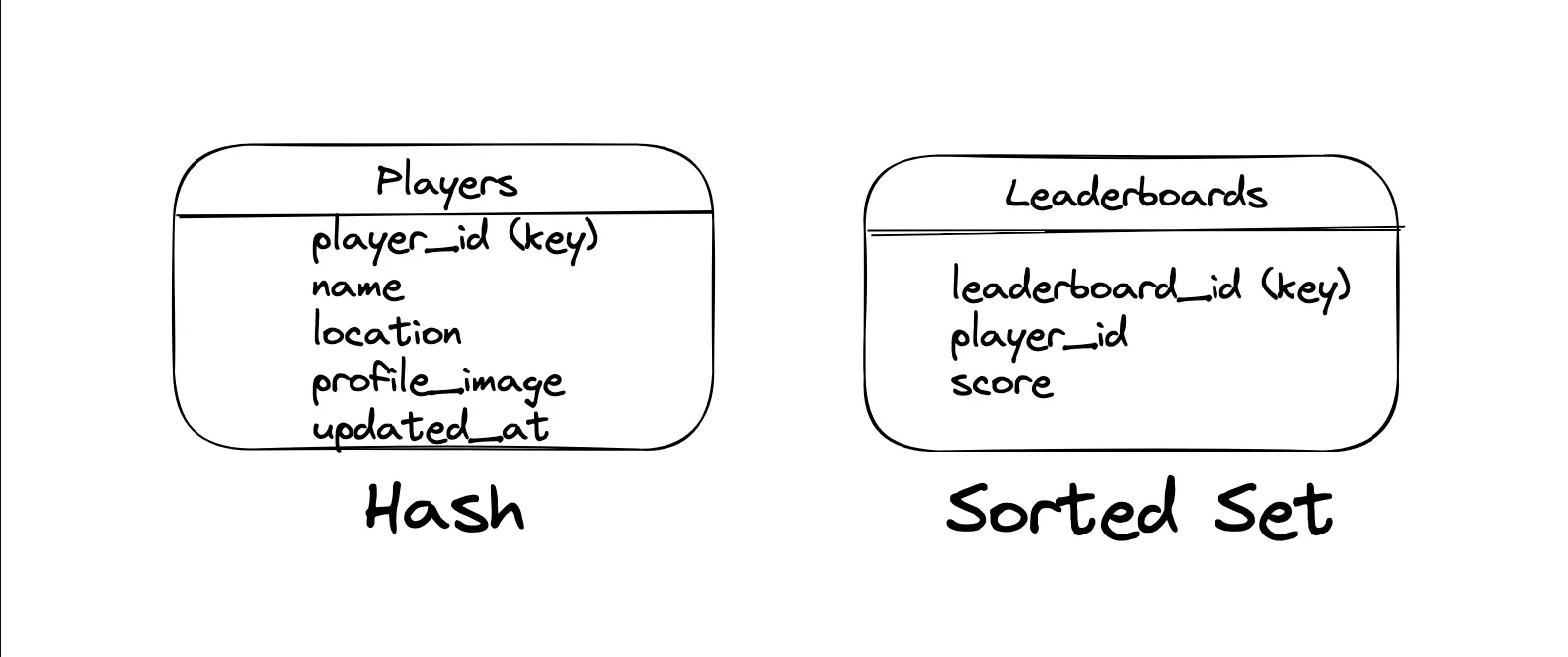
那么其他用户如何在分数变化之后计算排名呢?简单的想法就是直接更新 MySQL 数据库中的分数,然后获取所有小于该分数的用户数量。对于游戏这种分数频繁变化的场景,更新、查询数据库的磁盘 I/O 开销较大。如果能够将所有用户的分数信息缓存到 Redis 中,则可以直接使用跳表维护排行榜,然后使用消息队列异步更新数据库(类似后写缓存策略)。
像是算法比赛这种结束之后排名就不会变化的场景,数据库中也可以存储排名信息(而不只是分数)。如果内存中存不下所有用户的分数信息,可以对数据分片使用多个 Redis 节点维护排行榜,获取排名就需要对所有节点数据做聚合。应该也可以使用统计数据估算排名,返回给前端的是估算排名而不是真正的排名,然后后台使用定时任务去修正排名。
文章内容
排行榜分为绝对排行榜和相对排行榜,绝对排行榜显示 TopK 用户,相对排行榜显示指定用户周围的用户。HTTP 响应可以设置 cache-control: private, no-cache, must-revalidate, max-age=5 使用缓存,状态码 202 表示异步处理请求、401 表示身份未认证、403 表示没有权限,使用 HEAD 请求查看服务的健康状况。
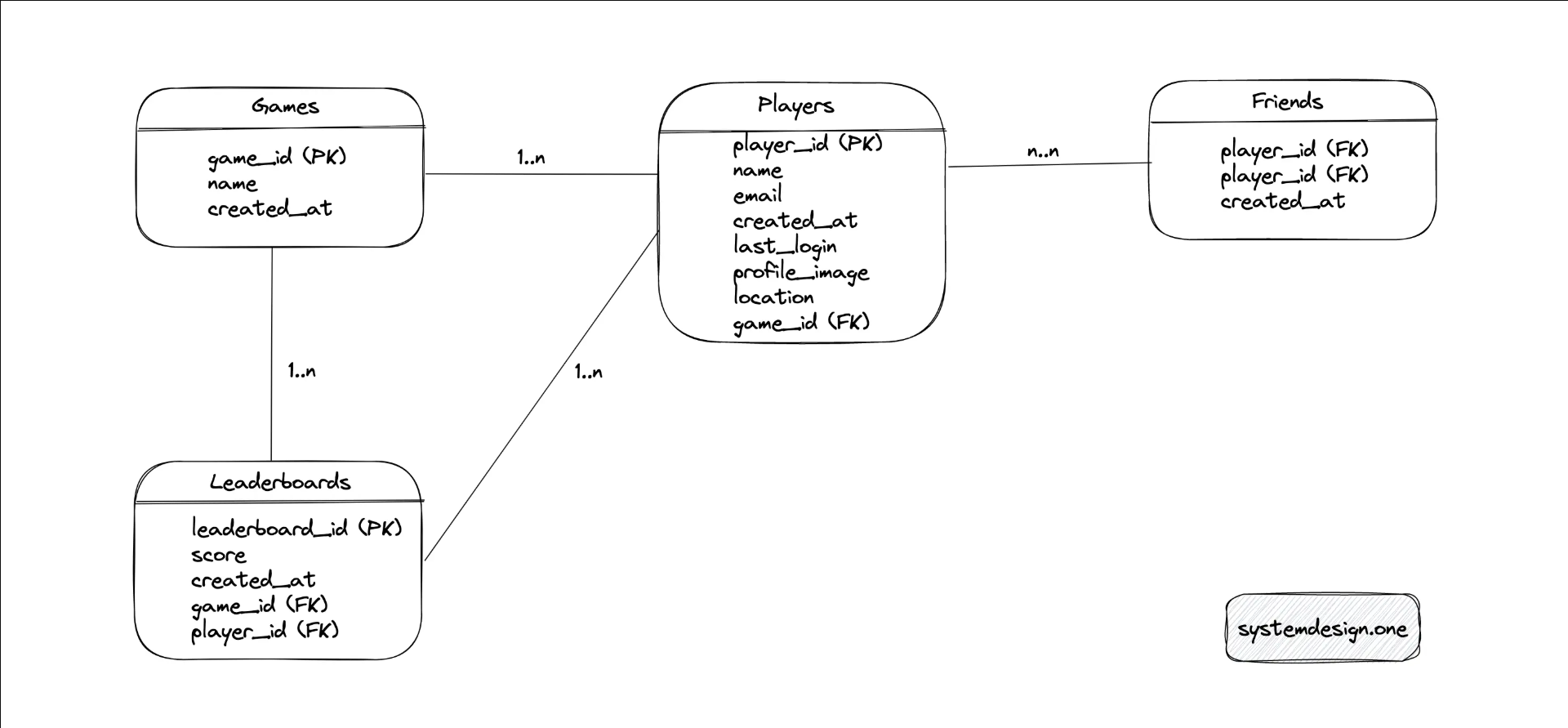
功能性需求:绝对和相对排行榜,可以查看指定用户的排名,排行榜可以划分为全球、区域和朋友圈,可以查看历史比赛的排行榜,可以根据每天/周/月的游戏情况进行排名,客户端以分布式的方式在全球范围内更新排行榜。流量特征:每天 5000 万个写入请求,读写比例为 5 : 1,用户分布在全球各地,排行榜需实时显示。
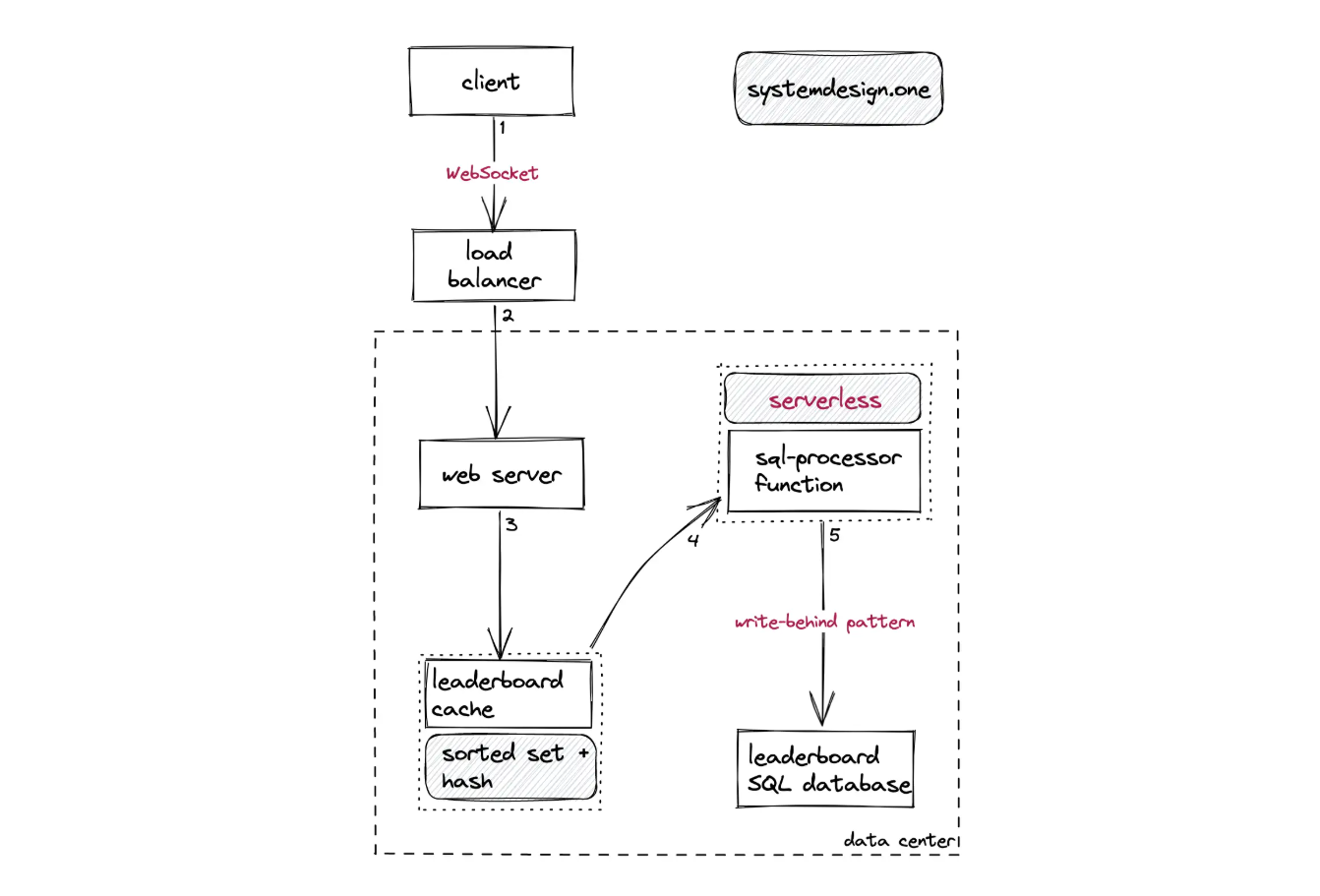
客户端使用 WebSocket 协议和负载均衡器建立连接,保证排行榜的实时性(允许服务器主动推送数据)。依然使用 DynamoDB 实现可扩展性,将玩家 ID 作为分区键、玩家得分作为排序键。东西有点多,看得有点懵,先实现再说。
遗漏的点
单个用户的分数变化会导致其他用户的排名也发生变化(导致缓存失效),所以使用 MySQL 数据库获取排名的方式需要全表扫描更新所有用户的排名,或者延迟更新每个用户的排名,磁盘 I/O 开销会比我之前想的更大。更新 MySQL 分数之后应该主动更新缓存而不是删除缓存(从 Cache Aside 变为类似 Write Through),确保所有用户都在 Redis 的排行榜中(所以也不能设置过期时间),避免重建整个排行榜。不过主动更新缓存可能导致不一致,例如网络原因导致缓存更新失败、并发更新的顺序交错导致旧数据覆盖新数据,可以使用消息队列排队、重试请求保证正确性。
一些疑问
Q:既然游戏和用户的关系是一对多,即不同游戏的用户不会共享,那么完全没有必要将不同游戏的数据耦合到一个数据库中。而且 Redis 维护的排行榜数据以 leaderboard_id 作为键是有问题的,这可是 Leaderboards 表的主键。