参考《高性能 MySQL》和官方文档。使用 MySQL 的 Sakila 示例数据库,使用 MySQL 版本 8.0.41 + InnoDB 存储引擎。各种术语的官方定义可以看 MySQL 术语表,锁相关的内容可以看 InnoDB Locking,更多数据库概念可以看 CUM 15-445 课程总结。任何描述都是简化的,不会涵盖所有情况,更多细节只能看文档。或者说没有必要去记细节,任何细节都取决于实现,而实现会随着版本更新而变化,需要学习的是整体的策略。
基本概念
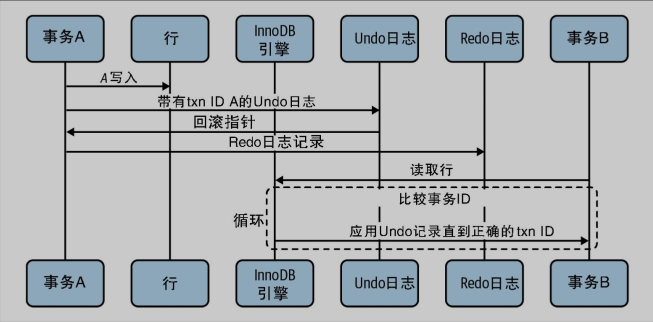
快照(snapshot):数据在特定时间的表示。一致性读(consistent read):根据快照显示查询结果,也被称为一致性非锁定读。在读已提交和可重复读隔离级别下执行 SELECT 语句的默认模式是一致性读,也就是说会使用多版本并发控制(MVCC)读取数据。读已提交在每次执行一致性读时都会重置快照,而可重复读只在第一次一致性读时建立快照。锁定读(locking read):使用 SELECT ... FOR SHARE 或者 SELECT ... FOR UPDATE 读取数据,会加读锁或者写锁,在事务提交或者回滚时释放(2PL)。
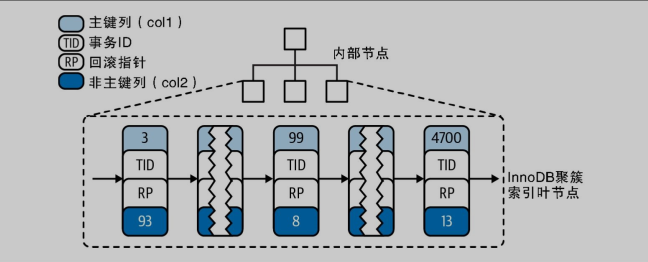
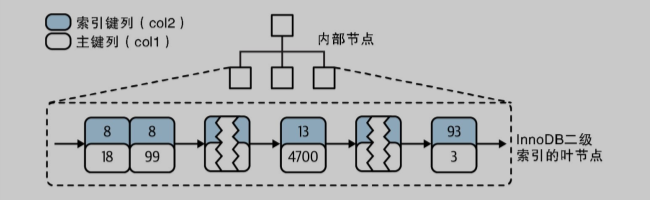
MVCC 是使用撤销日志(Undo Log)和读取视图(Read View)实现的。事务在修改记录之后会记录撤销日志,事务的回滚指针会指向该日志。读取视图包含一致性读不可见的事务 ID(事务 ID 不会在启动事务之后立即分配),读取记录时会比较记录的事务 ID 和读取视图,如果该记录对当前事务不可见,则执行撤销日志直到达到可见状态。删除操作被视为修改操作,通过修改删除标志位实现,只有当该版本记录对所有事务不可见时,才会被真正删除。撤销日志也会被记录到重做日志(Redo Log)中,实现崩溃恢复。
SELECT COUNT(c1) FROM t1 WHERE c1 = 'xyz'; -- Returns 0: no rows match. DELETE FROM t1 WHERE c1 = 'xyz'; -- Deletes several rows recently committed by other transaction.
SELECT COUNT(c2) FROM t1 WHERE c2 = 'abc'; -- Returns 0: no rows match. UPDATE t1 SET c2 = 'cba' WHERE c2 = 'abc'; -- Affects 10 rows: another txn just committed 10 rows with 'abc' values. SELECT COUNT(c2) FROM t1 WHERE c2 = 'cba'; -- Returns 10: this txn can now see the rows it just updated.
常用命令
1 2 3 4 5 6 7 8 9 10
SHOW FULL PROCESSLIST; SHOW ENGINE INNODB STATUS; SELECT * FROM performance_schema.data_locks\G SHOW STATUS LIKE 'Last_query_cost'; SHOW [GLOBAL | SESSION] VARIABLES [LIKE 'pattern' | WHERE expr]; START TRANSACTION; BEGIN; COMMIT; ROLLBACK; [CREATE | ALTER | DROP | OPTIMIZE | ANALYZE | CHECK | REPAIR ] TABLE tbl_name; SHOW TABLE STATUS [LIKE 'pattern' | WHERE expr]; SHOW INDEX FROM tbl_name; EXPLAIN [FORMAT=TREE | ANALYZE] select_statement; SHOW WARNINGS;
CREATE TABLE city_demo(city VARCHAR(50) NOT NULL); INSERT INTO city_demo(city) SELECT city FROM city; INSERT INTO city_demo(city) SELECT city FROM city_demo; -- 重复执行 5 次 UPDATE city_demo SET city = (SELECT city FROM city ORDER BY RAND() LIMIT 1); -- 随机化数据
SELECT COUNT(*) AS c, city FROM city_demo GROUP BY city ORDER BY c DESC LIMIT 10; +----+-----------------+ | c | city | +----+-----------------+ | 54 | Ondo | | 51 | London | | 49 | Olomouc | | 49 | Pontianak | | 47 | Kurgan | | 46 | Almirante Brown | | 46 | Changzhou | | 46 | Funafuti | | 46 | Jodhpur | | 45 | Plock | +----+-----------------+ SELECT COUNT(*) AS c, LEFT(city, 3) AS pref FROM city_demo GROUP BY pref ORDER BY c DESC LIMIT 10; +-----+------+ | c | pref | +-----+------+ | 477 | San | | 197 | Cha | | 171 | Tan | | 157 | al- | | 152 | Sou | | 148 | Bat | | 146 | Sal | | 146 | Shi | | 126 | Kam | | 125 | Val | +-----+------+ SELECT COUNT(*) AS c, LEFT(city, 7) AS pref FROM city_demo GROUP BY pref ORDER BY c DESC LIMIT 10; +----+---------+ | c | pref | +----+---------+ | 76 | San Fel | | 66 | Valle d | | 63 | Santiag | | 54 | Ondo | | 51 | London | | 49 | Pontian | | 49 | Olomouc | | 47 | Kurgan | | 46 | Jodhpur | | 46 | Almiran | +----+---------+
不能只根据前缀索引选择性的值确定前缀长度,例如前缀长度为 5 的选择性看上去很接近完整列的选择性,但是如果查看出现次数最多的前 10 个城市,和完整列的结果相比,会发现数据分布很不均匀。如果查询以 South 前缀的某个城市,那么回表的次数会更多。
如果优化器需要对多个索引做联合操作(由于多个 OR 条件),且索引的选择性不高时,通常会在缓存、排序和合并上消耗大量 CPU 和内存资源。然而,优化器不会将这些操作计算到查询成本中,优化器只关心随机页面读取,所以有时索引合并的性能还不如全表扫描。这还会影响并发的查询,此时使用 UNION 改写,将单个查询拆分为多个查询,可以避免单个查询的执行时间过长,影响其他并发的查询(由于 2PL 协议,单个查询会在提交时才释放锁,当然不同隔离级别有细微差别)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
EXPLAIN SELECT film_id, actor_id FROM film_actor WHERE actor_id = 1 OR film_id = 1\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: film_actor partitions: NULL type: index_merge possible_keys: PRIMARY,idx_fk_film_id key: PRIMARY,idx_fk_film_id key_len: 2,2 ref: NULL rows: 29 filtered: 100.00 Extra: Using union(PRIMARY,idx_fk_film_id); Using where
mysql> EXPLAIN SELECT COUNT(*) FROM film\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: film partitions: NULL type: index possible_keys: NULL key: idx_fk_language_id key_len: 1 ref: NULL rows: 1000 filtered: 100.00 Extra: Using index 1 row in set, 1 warning (0.00 sec)
mysql> SHOW WARNINGS\G *************************** 1. row *************************** Level: Note Code: 1003 Message: /* select#1 */ select count(0) AS `COUNT(*)` from `sakila`.`film` 1 row in set (0.00 sec)
IN & EXIST
常见的说法是,在子查询数据较少时使用 IN,而在子查询数据较大时使用 EXIST。因为使用 IN 是不相关子查询,会创建临时表,然后在临时表中查找匹配的数据。而使用 EXIST 是相关子查询,会直接在内表中查找匹配的数据(多次执行子查询)。但是,实际上优化器会做优化,使用 IN 并不意味着就会创建临时表。下面查询所有没有交易记录的顾客信息,执行计划显示该查询被转化为相关子查询,会使用覆盖索引查找匹配的数据。(推荐阅读 Optimizing Subqueries with the EXISTS Strategy)
mysql> SHOW WARNINGS\G *************************** 1. row *************************** Level: Note Code: 1003 Message: /* select#1 */ select `sakila`.`customer`.`customer_id` AS `customer_id`,`sakila`.`customer`.`store_id` AS `store_id`,`sakila`.`customer`.`first_name` AS `first_name`,`sakila`.`customer`.`last_name` AS `last_name`,`sakila`.`customer`.`email` AS `email`,`sakila`.`customer`.`address_id` AS `address_id`,`sakila`.`customer`.`active` AS `active`,`sakila`.`customer`.`create_date` AS `create_date`,`sakila`.`customer`.`last_update` AS `last_update` from `sakila`.`customer` semi join (`sakila`.`payment`) where (`sakila`.`payment`.`customer_id` = `sakila`.`customer`.`customer_id`) 1 row in set (0.00 sec)
mysql> EXPLAIN ANALYZE SELECT * FROM customer WHERE customer_id IN ( -> SELECT customer_id FROM payment -> )\G *************************** 1. row *************************** EXPLAIN: -> Nested loop semijoin (cost=271 rows=599) (actual time=0.0621..2.97 rows=599 loops=1) -> Table scan on customer (cost=61.2 rows=599) (actual time=0.048..0.401 rows=599 loops=1) -> Covering index lookup on payment using idx_fk_customer_id (customer_id=customer.customer_id) (cost=0.25 rows=1) (actual time=0.00418..0.00418 rows=1 loops=599)
mysql> SHOW WARNINGS\G *************************** 1. row *************************** Level: Note Code: 1276 Message: Field or reference 'sakila.customer.customer_id' of SELECT #2 was resolved in SELECT #1 *************************** 2. row *************************** Level: Note Code: 1003 Message: /* select#1 */ select `sakila`.`customer`.`customer_id` AS `customer_id`,`sakila`.`customer`.`store_id` AS `store_id`,`sakila`.`customer`.`first_name` AS `first_name`,`sakila`.`customer`.`last_name` AS `last_name`,`sakila`.`customer`.`email` AS `email`,`sakila`.`customer`.`address_id` AS `address_id`,`sakila`.`customer`.`active` AS `active`,`sakila`.`customer`.`create_date` AS `create_date`,`sakila`.`customer`.`last_update` AS `last_update` from `sakila`.`customer` semi join (`sakila`.`payment`) where (`<subquery2>`.`customer_id` = `sakila`.`customer`.`customer_id`) 2 rows in set (0.00 sec)
mysql> EXPLAIN ANALYZE SELECT * FROM customer WHERE EXISTS ( -> SELECT 1 FROM payment WHERE customer.customer_id = customer_id -> )\G *************************** 1. row *************************** EXPLAIN: -> Nested loop inner join (cost=963672 rows=9.64e+6) (actual time=6.27..6.92 rows=599 loops=1) -> Table scan on customer (cost=61.2 rows=599) (actual time=0.0789..0.422 rows=599 loops=1) -> Single-row index lookup on <subquery2> using <auto_distinct_key> (customer_id=customer.customer_id) (cost=3241..3241 rows=1) (actual time=0.0107..0.0107 rows=1 loops=599) -> Materialize with deduplication (cost=3241..3241 rows=16086) (actual time=6.18..6.18 rows=599 loops=1) -> Table scan on payment (cost=1633 rows=16086) (actual time=0.245..3.54 rows=16044 loops=1)
1 row in set, 1 warning (0.01 sec)
JOIN
确保 ON 或者 USING 的列上有索引。确保 GROUP BY 和 ORDER BY 只涉及一个表中的列,从而允许利用索引优化(松散/紧密索引扫描、利用索引排序)。如果需要对聚合的结果做超级聚合,可以使用 GROUP BY xxx WITH ROLLUP(注意查看查询计划,确定是否有性能问题),也可以使用其他等价语句或者在应用层聚合。
mysql> SHOW WARNINGS\G *************************** 1. row *************************** Level: Note Code: 1003 Message: /* select#1 */ select distinct `sakila`.`customer`.`customer_id` AS `customer_id`,`sakila`.`customer`.`store_id` AS `store_id`,`sakila`.`customer`.`first_name` AS `first_name`,`sakila`.`customer`.`last_name` AS `last_name`,`sakila`.`customer`.`email` AS `email`,`sakila`.`customer`.`address_id` AS `address_id`,`sakila`.`customer`.`active` AS `active`,`sakila`.`customer`.`create_date` AS `create_date`,`sakila`.`customer`.`last_update` AS `last_update` from `sakila`.`customer` join `sakila`.`payment` where (`sakila`.`payment`.`customer_id` = `sakila`.`customer`.`customer_id`) 1 row in set (0.00 sec)
优化方式:① 使用覆盖索引执行 LIMIT,索引中只包含必要的列(如 ORDER BY 的列,当然默认包含主键),那么 LIMIT 扫描的数据会减少很多,最后使用主键做连接得到完整数据。(不能使用 IN,因为 ERROR 1235 (42000): This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery')② 如果只允许顺序翻页的话,通过记录上个页面的边界值,下次查询就可以使用该值定位到目标位置,而不会做无效的扫描。③ 一次性获取多页数据,在应用层缓存起来(类似缓存 I/O)。④ 其他方法,使用预先计算的汇总表,或者使用冗余表。
SET @@GLOBAL.local_infile = 1; CREATE TABLE test (num TINYINT NOT NULL, dummy TINYINT NOT NULL DEFAULT 0); LOAD DATA LOCAL INFILE 'data.txt' INTO TABLE test (num); ALTER TABLE test ADD INDEX idx_num (num);
mysql> EXPLAIN SELECT * FROM test WHERE num NOT IN (1, 2)\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: test partitions: NULL type: range possible_keys: idx_num key: idx_num key_len: 1 ref: NULL rows: 3 filtered: 100.00 Extra: Using index condition 1 row in set, 1 warning (0.00 sec)
mysql> SHOW WARNINGS\G *************************** 1. row *************************** Level: Note Code: 1003 Message: /* select#1 */ select `sakila`.`test`.`num` AS `num`,`sakila`.`test`.`dummy` AS `dummy` from `sakila`.`test` where (`sakila`.`test`.`num` not in (1,2)) 1 row in set (0.00 sec)
mysql> EXPLAIN ANALYZE SELECT * FROM test WHERE num NOT IN (1, 2)\G *************************** 1. row *************************** EXPLAIN: -> Index range scan on test using idx_num over (num < 1) OR (1 < num < 2) OR (2 < num), with index condition: (test.num not in (1,2)) (cost=3.38 rows=3) (actual time=0.0355..0.0383 rows=1 loops=1)
1 row in set (0.00 sec)
mysql> EXPLAIN SELECT * FROM test WHERE num NOT IN (3)\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: test partitions: NULL type: ALL possible_keys: idx_num key: NULL key_len: NULL ref: NULL rows: 1996905 filtered: 50.00 Extra: Using where 1 row in set, 1 warning (0.00 sec)
mysql> SHOW WARNINGS\G *************************** 1. row *************************** Level: Note Code: 1003 Message: /* select#1 */ select `sakila`.`test`.`num` AS `num`,`sakila`.`test`.`dummy` AS `dummy` from `sakila`.`test` where (`sakila`.`test`.`num` <> 3) 1 row in set (0.00 sec)
mysql> EXPLAIN ANALYZE SELECT * FROM test WHERE num NOT IN (3)\G *************************** 1. row *************************** EXPLAIN: -> Filter: (test.num <> 3) (cost=201305 rows=998453) (actual time=0.0239..1133 rows=2e+6 loops=1) -> Table scan on test (cost=201305 rows=2e+6) (actual time=0.0222..976 rows=2e+6 loops=1)