参考 Caffeine GitHub,Design of a Modern Cache,Cache Eviction and Expiration Policy,幻灯片。
计数方式
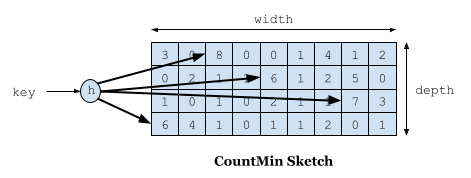
Count-min Sketch 是一种概率数据结构,底层使用计数器矩阵和多个哈希函数,原理类似布隆过滤器。添加元素会递增每行的计数器,取最小值作为频率的估计值,每行计数器的位置使用哈希函数计算得到。
执行流程
首先,新元素会进入 Window Cache,被 LRU 淘汰之后会尝试进入 Main Cache。W-TinyLFU 使用 Count-min Sketch 作为过滤器,被 Window Cache 淘汰的新元素会和 Main Cache 中 Probation 段即将淘汰的元素比较,如果新元素的访问频率更高则可以进入 Main Cache。Main Cache 的淘汰流程类似 Linux Page Cache,如果元素在 Probation 段,再次访问会升级到 Protected 段,长期不访问会降级/淘汰。计数器会定期衰减,以适应访问模式的变化。
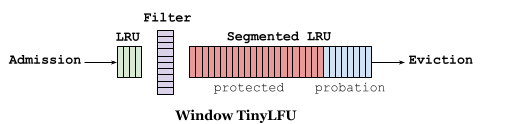
Filter 可以有效减少顺序扫描导致的缓存污染,同时 Window Cache 给新元素提供增加频率的机会。较小的准入窗口适合偏向频率的负载,不适合偏向时间的负载。因为在偏向时间的负载中,元素可能还没来得及增加频率就被淘汰。可以使用爬山法(启发式算法)来选择最佳的窗口大小,当命中率发生较大变化时,就会触发该过程,以适应不同负载。
过期策略
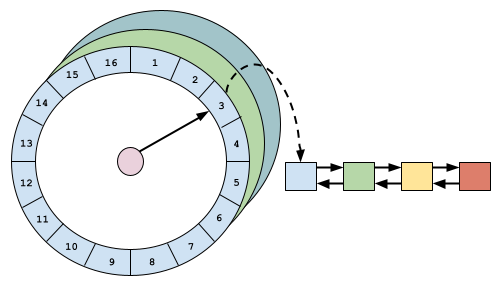
Caffeine 根据过期时间是否固定来选择过期删除策略。如果过期时间固定,则使用 LRU 列表维护元素的过期顺序。如果过期时间可变,则使用分层时间轮算法,时间复杂度为 $O(1)$。多个时间轮可以表示不同的时间层级,例如例如天、小时、分钟和秒。单个时间轮是一个双向链表数组,每个链表代表一个粗略的时间跨度(在当前时间层级内)。
当上层时间轮转动时,上层时间轮的下一个桶会被刷新到下层时间轮,这些元素会被重新哈希并放置在相应的位置。例如,一天之后过期的元素在天数层级的时间轮中,一天之后,天数层级的时间轮转动,桶内元素需要以小时为跨度放置到下层时间轮。当最底层时间轮转动时,最底层时间轮的上一个桶中的元素会被逐出,因为元素已经过期。
并发设计
在大多数缓存淘汰策略中,读操作也会修改共享状态(策略信息),例如 LRU 的移动元素、LFU 的更新计数。为保证更新策略信息的线程安全,使用全局独占锁会有性能问题,使用分段锁也无法避免热点元素导致的性能问题(并发竞争单个锁)。另一种方法是将操作记录到缓冲区,然后异步批量处理,用于更新策略信息(读写哈希表不会阻塞)。
When contention becomes a bottleneck the next classic step has been to update only per entry metadata and use either a random sampling or a FIFO-based eviction policy. Those techniques can have great read performance, poor write performance, and difficulty in choosing a good victim.(没有看懂)
Caffeine 使用缓冲区优化,减少并发更新策略信息的锁竞争导致的性能问题,读写操作使用不同的缓冲区。读操作使用条带化的环形缓冲区,根据线程的哈希值选择条带,而不是元素的哈希值,避免热点元素导致的竞争问题。当检测到竞争时,会自动增加条带。当环形缓冲区已满时,触发异步批量处理(只需获取一次锁),此时会丢弃对该缓冲区的后续添加,直到空间可用。被丢弃的读操作依然会将缓存值返回给调用者,只是不会更新策略信息,部分策略信息的丢失不会对性能产生太大影响。
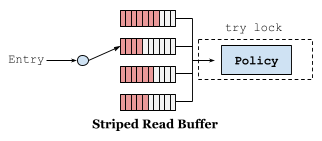
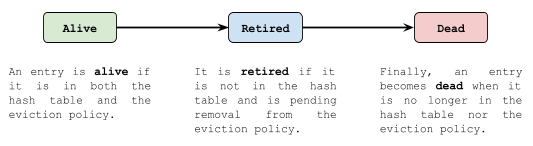
写操作使用单个并发队列,会逐个而不是批量处理,不允许丢失。读写缓冲区都是多生产者单消费者的模式。使用缓冲区异步更新策略,无法保证按照增删改查操作实际发生的顺序更新,可以会发生悬空引用,即哈希表中已经删除但是策略中却保留某个元素的信息,Caffeine 使用状态机定义元素的生命周期来解决该问题。
个人理解,缓冲区优化主要是异步批量处理策略信息的更新,避免阻塞读写哈希表,避免频繁获取锁。Caffeine 缓存的元素是可以随时淘汰的,而磁盘页面缓冲池还需要判断页面是否被 Pin。
源码分析
1 | // TODO |