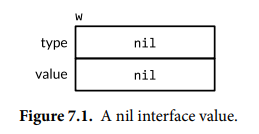
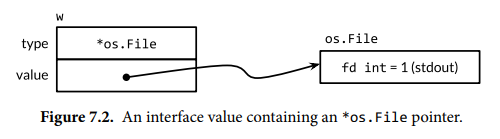
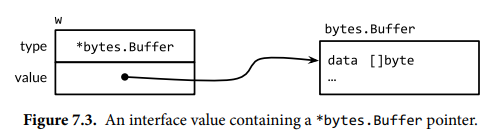
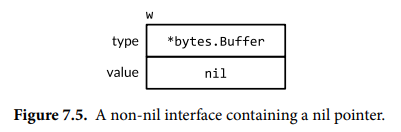
It is possible for processors to do that in general, but x86 doesn’t, so you don’t need a barrier there. Search for “total store order” if you’re curious.
大多数指令集架构不提供顺序一致的内存模型,因为更强的一致性通常意味着更少的优化(更低的性能)。x86 使用 Total Store Order(TSO)内存模型:所有处理器都连接到单个共享内存,但是每个处理器有一个本地的写入队列,写入操作排队写入共享内存,读取操作会优先读取本地写入队列中的值(如果有的话)。ARM/POWER 的内存模型更加宽松:每个处理器从自己的内存完整副本中读取和写入,读取可以延迟到写入之后,并且每个写入都独立地传播到其他处理器,在写入传播时允许重新排序。
JMM 为程序中所有操作定义了一个偏序关系,称为 Happens-Before。操作 A Happens-Before 操作 B 的含义是:如果操作 A 先于操作 B 发生,那么执行操作 B 的线程能够看到操作 A 的结果。如果两个操作没有 Happens-Before 关系,那么 JVM/CPU 可以对它们任意地重新排序。
关于 GOMAXPROCS,runtime 文档的描述如下:The GOMAXPROCS variable limits the number of operating system threads that can execute user-level Go code simultaneously. There is no limit to the number of threads that can be blocked in system calls on behalf of Go code; those do not count against the GOMAXPROCS limit.
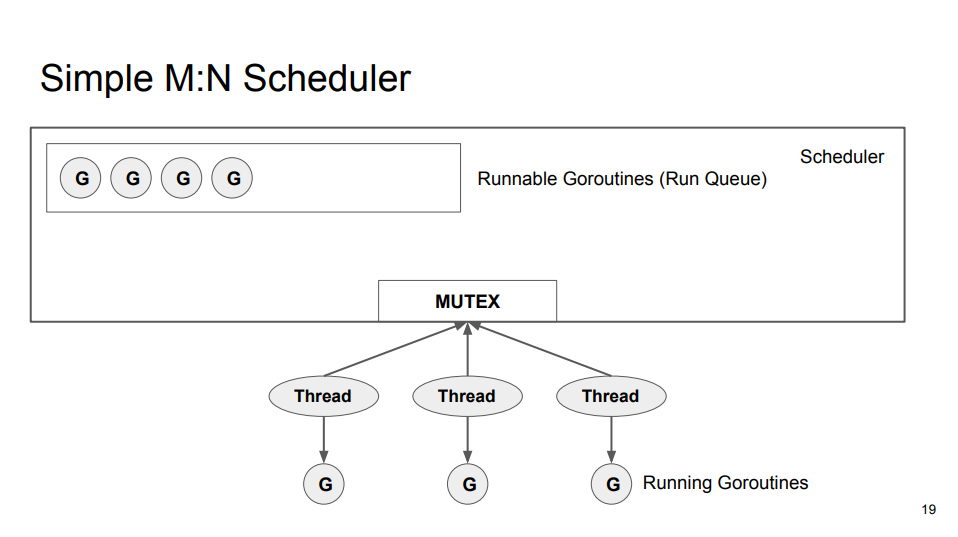
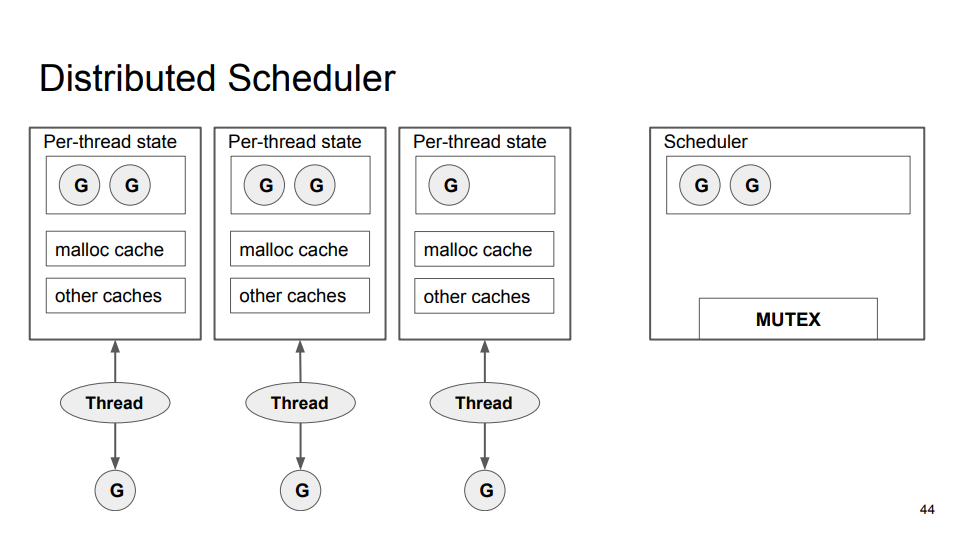
该实现的瓶颈在全局的互斥锁(MUTEX),内核线程创建 Goroutine 以及获取 Goroutine 都需要操作共享的 Run Queue。解决方案很容易想到,就是为每个内核线程创建本地变量,从而避免频繁访问全局的共享变量。该方案会增加获取下一个 Goroutine 的复杂性,Go 调度器实现的获取顺序是, Local Run Queue、Global Run Queue、Network Poller、Work Stealing。
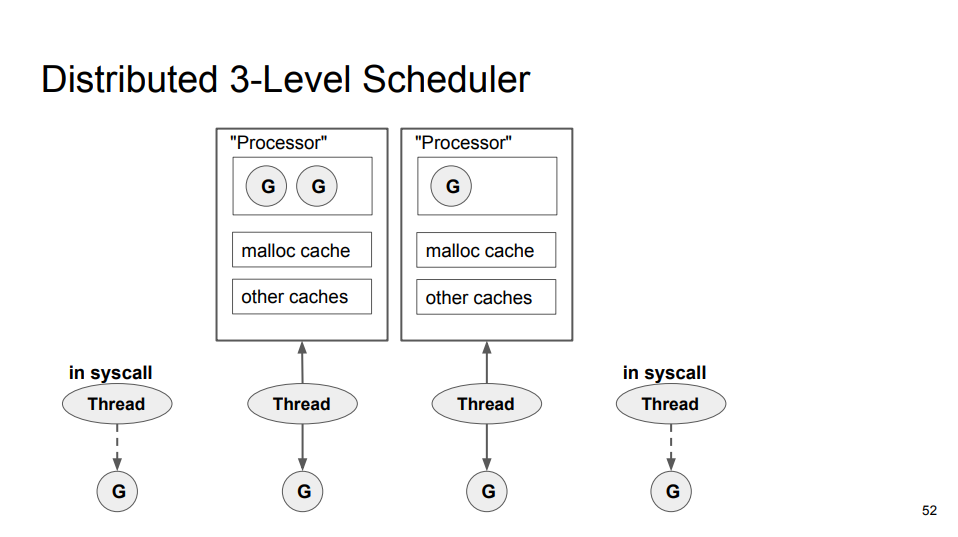
由于发生系统调用时会创建/唤醒内核线程,也就是说内核线程的数量会多于 CPU 的核心数量。新的调度器为每个内核线程分配本地资源,但是实际上执行 Go 代码的内核线程的数量是固定的(由 GOMAXPROCS 指定),所以空闲线程不应该持有资源,会造成资源浪费以及降低 Work Stealing 的效率。所以,设计上引入一个新的实体,也就是处理器(Processor),从而调度模型从 GM 变为 GMP。Go runtime 不会为每个内核线程分配资源,而是为 Processor 分配资源,Processor 的数量就是 CPU 的核心数量。在新的模型中,当 Goroutine 发生系统调用时,Goroutine 会创建/唤醒新的内核线程,然后将 Processor 对象交给新的内核线程。
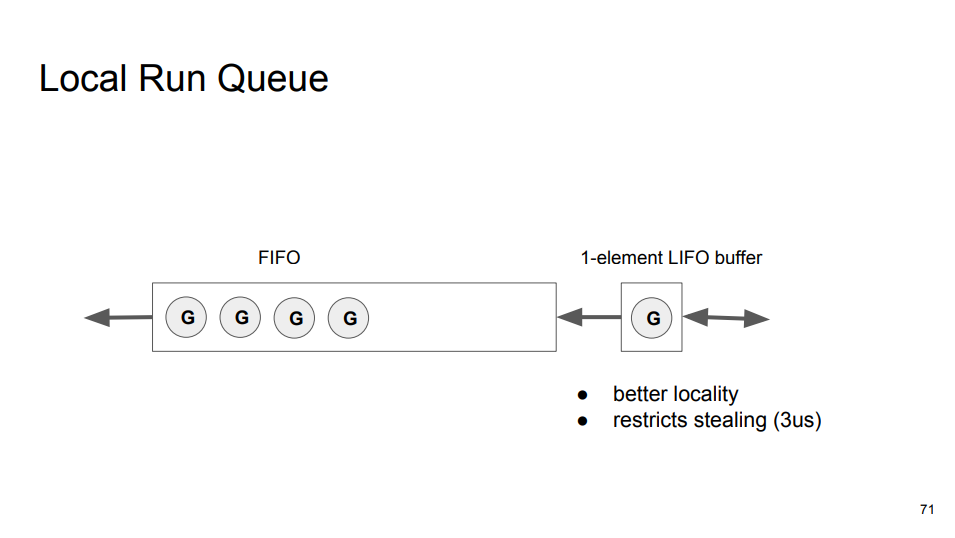
目前,调度器已经足够好,不过可以更好。公平性(Fairness)和性能的权衡:设计者想要以最小的性能开销获得最小的公平性。FIFO 队列可以一定程度上保证公平性,但是如果当前 Goroutine 陷入无限循环,队列中的 Goroutine 将会饥饿,所以设计者使用 10 ms 的时间片轮转调度(时分共享,抢占式)。另一方面,FIFO 队列缺少局部性(影响性能),最后进入队列的 Goroutine 会在最后运行。常见的场景,当前 Goroutine 创建另一个 Goroutine,然后自身被阻塞等待另一个 Goroutine 执行。缺少局部性的 FIFO 会产生很大延迟,所以设计者在 Local Run Queue 的尾部添加一个单元素的 LIFO 缓冲区,每次获取 Goroutine 都会首先从缓冲区中获取(Direct Switch)。
如果 Local Run Queue 一直不为空,Global Run Queue 会饥饿。所以,假设当前是第 schedTick 次获取,设计者设置当 schedTick % 61 == 0 时,优先从 Global Run Queue 获取 Goroutine。为什么使用 61,因为 61 不大不小,太大会饥饿,太小会因为 Global Run Queue 的 MUTEX 限制性能,并且参考哈希表的设计,使用质数而不是 2 的幂会更随机/公平。
最后,Network Poller 可能会饥饿,解决方案是使用后台线程从中定期获取 Goroutine。之所以不像处理 Global Run Queue 饥饿一样在当前线程中获取,是因为从 Network Poller 获取 Goroutine 涉及到 epoll_wait() 系统调用(很慢)。
某些标记之后的换行符会被转换为分号,因此换行符的位置对于正确解析 Go 代码至关重要。例如,函数的左括号 { 必须与函数声明的结尾在同一行,否则会报错 unexpected semicolon or newline before {。而在表达式 x + y 中,可以在 + 运算符之后换行,但不能在之前换行。
1 2 3
funcmain() { fmt.Println("Hello, 世界") }
Command-Line Arguments
可以使用 os.Args 变量获取命令行参数,该变量是一个字符串切片。os.Args[0] 是命令本身,剩余元素是程序启动时用户传递的参数。使用 var 声明语句定义变量,变量可以在声明时进行初始化。如果未显式初始化,则隐式初始化为该类型的零值(zero value),数值类型为 0,字符串类型为空串 ""。
for 语句是 Go 中唯一的循环语句,可以充当其他语言中常规的 for、while 循环以及无限循环。Go 语言不允许未使用的局部变量,否则会报错 declared and not used。使用 += 在循环中拼接字符串的开销较大,每次都会生成新字符串,而旧字符串则不再使用等待 GC,可以使用 strings.Join 方法提升性能,一次性拼接所有字符串。
var palette = []color.Color{color.White, color.Black}
const ( whiteIndex = 0// first color in palette blackIndex = 1// next color in palette )
funcmain() { //!-main // The sequence of images is deterministic unless we seed // the pseudo-random number generator using the current time. // Thanks to Randall McPherson for pointing out the omission. rand.Seed(time.Now().UTC().UnixNano())
变量声明的通用形式为 var name type = expression。如果省略 type 则类型由表达式推断,如果省略 = expression 则必须显式指定类型,初始值为该类型的零值。数值类型为 0,字符串类型为空串 "",布尔类型为 false,接口和引用类型(切片、指针、哈希表、通道和函数)为 nil。像数组或者结构体聚合类型的元素或字段的零值就是自身的零值。
零值机制确保变量始终有其类型所定义的明确值,Go 语言中不存在未初始化变量的概念。可以同时声明一组变量,如果省略类型则可以同时声明不同类型的变量。包级变量会在 main 函数开始之前初始化,局部变量在声明时初始化。
1 2 3
var i, j, k int// int, int, int var b, f, s = true, 2.3, "four"// bool, float64, string var f, err = os.Open(name) // os.Open returns a file and an error
Short Variable Declarations
在函数中可以使用简短变量声明(short variable declaration)的形式声明和初始化局部变量,形式为 name := expression。简短变量声明常用于声明和初始化大多数局部变量,而 var 声明常用于变量类型和表达式类型不同、或者稍后赋值且初始值不重要的局部变量。
1 2 3
i := 100// an int var boiling float64 = 100// a float64 i, j = j, i // swap values of i and j
x := 1 p := &x // p, of type *int, points to x fmt.Println(*p) // "1" *p = 2// equivalent to x = 2 fmt.Println(x) // "2"
函数返回局部变量的地址是安全的,即使函数调用返回该局部变量 v 仍会存在。由编译器逃逸分析确定,该变量会在堆上分配。根据静态分析知识,为保证安全性,分析肯定是偏向误报(Sound)而不是漏报(Complete)。每次调用函数 f 返回的值都不同。每次获取变量的地址或者复制指针时,都会为该变量创建新的别名(aliases),*p 是 v 的别名。
1 2 3 4 5
var p = f() funcf() *int { v := 1 return &v }
1 2 3 4 5 6 7 8 9 10
var n = flag.Bool("n", false, "omit trailing newline") var sep = flag.String("s", " ", "separator")
另一种创建变量的方式是使用内置函数 new,表达式 new(T) 创建类型为 T 的未命名变量,将其初始化为类型 T 的零值,返回类型为 *T 的地址值。使用 new 创建的变量和普通局部变量没有区别,只是后者需要显式获取地址。
1 2 3 4 5 6 7 8
funcnewInt() *int { returnnew(int) }
funcnewInt() *int { var dummy int return &dummy }
通常每次调用 new 都会返回具有唯一地址的不同变量,例外情况是,如果两个变量的类型不携带任何信息且大小为零(例如 struct{} 或 [0]int),则根据实现的不同可能会具有相同的地址(实测得到的是不同地址)。由于 new 是内置函数而不是关键字,所以可以被重新定义为其他东西,不过此时不能在 delta 中使用内置的 new 函数。
1
funcdelta(old, newint)int { returnnew - old }
Lifetime of Variables
变量的声明周期是指其在程序执行过程中的存活时间。包级变量在整个程序执行过程中存活,局部变量在声明时创建,在不被引用时回收(GC 可达性分析)。因为变量的生命周期取决于可达性,所以局部变量在函数返回之后仍有可能存活。编译器会决定将变量分配到堆中还是栈中,这一决定并非取决于使用 var 还是 new 来声明变量(Pointers 小节中提到过的逃逸分析)。例如,下面示例中 x 必须在堆上分配,而 y 可以在栈上分配。
1 2 3 4 5 6 7 8 9 10 11 12
var global *int
funcf() { var x int x = 1 global = &x }
funcg() { y := new(int) *y = 1 }
Assignments
Go 语言中仅有后置 x++ 和 x-- 而没有前置写法,而且该操作被视为语句而不是表达式,所以不能将其赋值给变量或者参与运算。
类型声明形如 type name underlying-type,用于定义一个新的具有某个底层类型(underlying type)的命名类型(named type)。即使两个类型具有相同的底层类型,它们也是不同的类型,不能直接比较或组合,而需要使用 T(x) 进行显式类型转换。命名类型将底层类型的不同使用方式区分开来,避免不同使用方式之间混淆。
if x := f(); x == 0 { fmt.Println(x) } elseif y := g(x); x == y { fmt.Println(x, y) } else { fmt.Println(x, y) } fmt.Println(x, y) // compile error: x and y are not visible here
Basic Data Types
Go 语言的类型分为四类:基本类型、聚合类型、引用类型和接口类型。基本类型包括数值类型、字符串和布尔类型,聚合类型包括数组和结构体,引用类型包括指针、切片、哈希表、函数和通道。
var x complex128 = complex(1, 2) // 1+2i var y complex128 = complex(3, 4) // 3+4i fmt.Println(x*y) // "(-5+10i)" fmt.Println(real(x*y)) // "-5" fmt.Println(imag(x*y)) // "10"
Strings
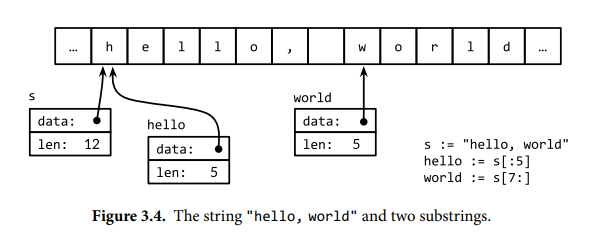
字符串是不可变的字节序列,内置函数 len 返回字符串的字节数量,而不是字符数量,索引操作 s[i] 获取字符串 s 的第 i 个字节。字符串的第 i 个字节不一定就是第 i 个字符,因为非 ASCII 码点的 UTF-8 编码需要多个字节。使用 s[i:j] 可以获取子字符串,该子字符串是一个新的字符串,不过和原串共享底层字节数组。由于可以共享底层内存,所以字符串的复制和子串操作的开销很低。
1 2 3
s := "hello, world" fmt.Println(len(s)) // "12" fmt.Println(s[0], s[7]) // "104 119" ('h' and 'w')
// "program" in Japanese katakana s := "プログラム" fmt.Printf("% x\n", s) // "e3 83 97 e3 83 ad e3 82 b0 e3 83 a9 e3 83 a0" r := []rune(s) fmt.Printf("%x\n", r) // "[30d7 30ed 30b0 30e9 30e0]"
Strings and Byte Slices
字符串 s 可以使用 []byte(s) 转换为字节切片,然后使用 string(b) 转换回来。两个操作通常都会进行复制操作,以确保 b 的可变性和 s2 的不可变性。bytes 包提供 Buffer 类型,类似 Java 中的 StringBuilder,该类型无需初始化,其零值可以直接使用,因为之后调用的方法中会判断底层切片 buf 是否为 nil,然后为其分配内存。
1 2 3
s := "abc" b := []byte(s) s2 := string(b)
Conversions between Strings and Numbers
1 2 3 4 5 6
x := 123 y := fmt.Sprintf("%d", x) fmt.Println(y, strconv.Itoa(x)) // "123 123"
x, err := strconv.Atoi("123") // x is an int y, err := strconv.ParseInt("123", 10, 64) // base 10, up to 64 bits
Constants
const 常量的底层类型必须是基本类型(和 Java 中的 final 很不一样)。当常量作为一个组声明时,除该组的第一个元素外,剩余元素的右侧表达式可以省略,此时默认会使用之前元素的表达式。
1 2 3 4 5 6 7
const ( a = 1 b c = 2 d ) fmt.Println(a, b, c, d) // "1 1 2 2"
The Constant Generator iota
可以使用常量生成器 iota 创建枚举常量组,iota 的值从 0 开始,每次递增 1。
1 2 3 4 5 6 7 8
type Flags uint const ( FlagUp Flags = 1 << iota// is up FlagBroadcast // supports broadcast access capability FlagLoopback // is a loopback interface FlagPointToPoint // belongs to a point-to-point link FlagMulticast // supports multicast access capability )
var x float32 = math.Pi var y float64 = math.Pi var z complex128 = math.Pi
const Pi64 float64 = math.Pi var x float32 = float32(Pi64) var y float64 = Pi64 var z complex128 = complex128(Pi64)
只有常量可以不指定类型,当将无类型常量赋值给变量时,该常量会隐式转换为变量的类型。
1 2 3 4
var f float64 = 3 + 0i// untyped complex -> float64 f = 2// untyped integer -> float64 f = 1e123// untyped floating-point -> float64 f = 'a'// untyped rune -> float64
无论隐式还是显式转换,在转换时目标类型必须能够表示原始值,对于实数和复数的浮点数,允许四舍五入。
1 2 3 4 5 6 7 8 9
const ( deadbeef = 0xdeadbeef// untyped int with value 3735928559 a = uint32(deadbeef) // uint32 with value 3735928559 b = float32(deadbeef) // float32 with value 3735928576 (rounded up) c = float64(deadbeef) // float64 with value 3735928559 (exact) d = int32(deadbeef) // compile error: constant overflows int32 e = float64(1e309) // compile error: constant overflows float64 f = uint(-1) // compile error: constant underflows uint )
在未显式指定类型的变量声明中,无类型常量的特性会决定变量的默认类型。无类型整型默认转换为 int 类型,无类型浮点数和复数默认转换为 float64 和 complex128。如果要使用其他类型,需要显示类型转换,或者在变量声明中指定类型。在将无类型常量转换为接口值时,默认值非常重要,因为它们会决定接口的动态类型。
1 2 3 4
i := 0// untyped integer; implicit int(0) r := '\000'// untyped rune; implicit rune('\000') f := 0.0// untyped floating-point; implicit float64(0.0) c := 0i// untyped complex; implicit complex128(0i)
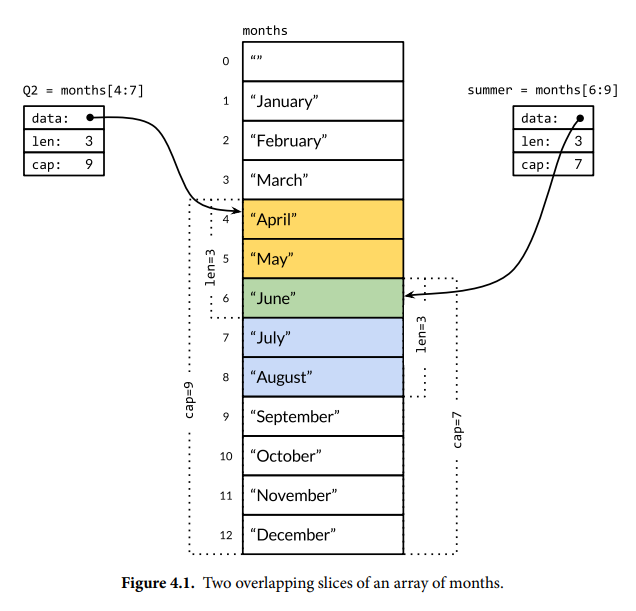
fmt.Println(summer[:20]) // panic: out of range endlessSummer := summer[:5] // extend a slice (within capacity) fmt.Println(endlessSummer) // "[June July August September October]"
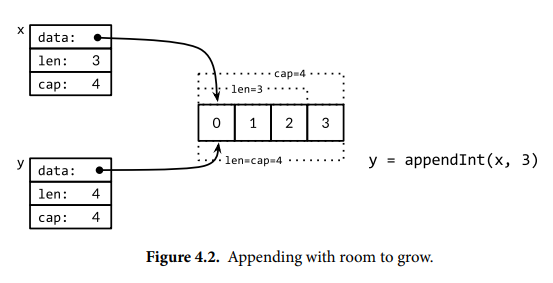
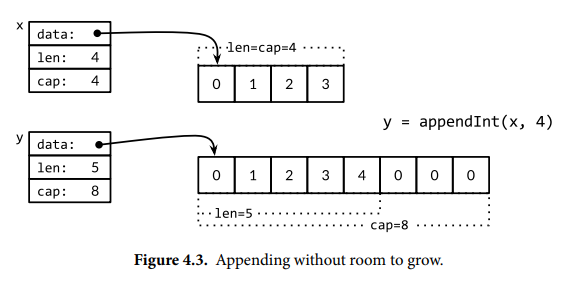
funcappendInt(x []int, y int) []int { var z []int zlen := len(x) + 1 if zlen <= cap(x) { // There is room to grow. Extend the slice. z = x[:zlen] } else { // There is insufficient space. Allocate a new array. // Grow by doubling, for amortized linear complexity. zcap := zlen if zcap < 2*len(x) { zcap = 2 * len(x) } z = make([]int, zlen, zcap) copy(z, x) // a built-in function; see text } z[len(x)] = y return z }
_ = &ages["bob"] // compile error: cannot take address of map element
可以使用基于范围的 for 循环遍历哈希表。map 的迭代顺序不是确定性的,实际实现为随机顺序,如果要按照顺序遍历,需要对键进行排序。由于已知 names 的最终大小,所以预分配指定容量的数组会更高效。
1 2 3 4 5 6 7 8
names := make([]string, 0, len(ages)) for name := range ages { names = append(names, name) } sort.Strings(names) for _, name := range names { fmt.Printf("%s\t%d\n", name, ages[name]) }
funcadd(x int, y int)int { return x + y } funcsub(x, y int) (z int) { z = x - y; return } funcfirst(x int, _ int)int { return x } funczero(int, int)int { return0 }
f = product // compile error: can't assign f(int, int) int to f(int) int
Anonymous Functions
命名函数只能在包级进行声明,而匿名函数可以在任意表达式中使用。每次调用 squares 都会创建一个局部变量 x,并返回一个类型为 func() int 的匿名函数。此时,匿名函数可以访问和修改外层函数的局部变量 x。这些隐含的变量就是将函数视为引用类型,以及函数值之间无法比较的原因。这类函数值使用闭包(closures)技术实现。就像之前提到的返回局部变量的地址的例子,闭包示例也说明变量的生命周期不是由作用域决定,而是由可达性决定。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// squares returns a function that returns // the next square number each time it is called. funcsquares()func()int { var x int returnfunc()int { x++ return x * x } }
functriple(x int) (result int) { deferfunc() { result += x }() return double(x) }
fmt.Println(triple(4)) // "12"
Panic
当 Go 运行时检测到严重的错误时,会产生 panic,正常执行会停止,从函数栈顶到 main 函数的所有延迟函数调用会依次执行,然后程序会崩溃并记录日志。可以显示调用内置的 painc 函数。对于函数的前置条件进行确认是良好的做法,但是除非能够提供更详细的错误信息或更早地检测到错误,否则没有必要去确认在运行时会自动检查的条件。
1 2 3 4 5 6
funcReset(x *Buffer) { if x == nil { panic("x is nil") // unnecessary! } x.elements = nil }
funcParse(input string) (s *Syntax, err error) { deferfunc() { if p := recover(); p != nil { err = fmt.Errorf("internal error: %v", p) } }() // ...parser... }
Methods
Method Declarations
方法声明就是在函数名之前添加额外的参数,该参数将函数和该参数的类型绑定。额外的参数 p 被称作该方法的接收者(receiver),在 Go 语言中,没有使用 this 或 self 表示接收者,而是像对待普通参数一样选择接收者的名称,通常使用类型的首字母作为其名称。以下两个函数声明不会相互冲突,一个是包级函数,另一个是 Point 类型的方法。
在 Go 语言中,字段和方法不能同名(和 Java 不同)。和其他面向对象语言不同,Go 中可以为大多数类型定义方法,而不仅仅是结构体类型。例外情况是:① 不能直接为基本类型定义方法,而必须使用 type 创建命名类型;② 不能为指针和接口类型定义方法,但是接收者可以是指向非指针类型的指针。另外,类型和方法必须定义在相同的包中。
1 2 3 4 5 6 7 8 9 10 11
type Point struct{ X, Y float64 }
// traditional function funcDistance(p, q Point)float64 { return math.Hypot(q.X-p.X, q.Y-p.Y) }
// same thing, but as a method of the Point type func(p Point) Distance(q Point) float64 { return math.Hypot(q.X-p.X, q.Y-p.Y) }
funcmain() { var buf *bytes.Buffer if debug { buf = new(bytes.Buffer) // enable collection of output } f(buf) // NOTE: subtly incorrect! if debug { // ...use buf... } }
// If out is non-nil, output will be written to it. funcf(out io.Writer) { // ...do something... if out != nil { out.Write([]byte("done!\n")) // panic: nil pointer dereference } }
Type Assertions
类型断言(type assertion)是对接口值执行的操作,形如 x.(T),其中 x 是接口类型的表达式,T 是断言类型。如果 T 是具体类型,那么类型断言会检查 x 的动态类型是否和 T 相同,如果相同则返回 x 的动态值,否则引发 panic。
1 2 3 4
var w io.Writer w = os.Stdout f := w.(*os.File) // success: f == os.Stdout c := w.(*bytes.Buffer) // panic: interface holds *os.File, not *bytes.Buffer
如果 T 是接口类型,那么类型断言会检查 x 的动态类型是否满足 T,如果满足则返回类型为 T 的接口值,该接口值和 x 具有相同的动态类型和动态值。不论 T 是什么类型,如果 x 是 nil,则断言会失败。
1 2 3 4 5
var w io.Writer w = os.Stdout rw := w.(io.ReadWriter) // success: *os.File has both Read and Write w = new(ByteCounter) rw = w.(io.ReadWriter) // panic: *ByteCounter has no Read method
如果使用以下类型断言方式,则断言失败不会引发 panic,而是额外返回 false。
1 2 3
var w io.Writer = os.Stdout f, ok := w.(*os.File) // success: ok, f == os.Stdout b, ok := w.(*bytes.Buffer) // failure: !ok, b == nil
Type Switches
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
funcsqlQuote(x interface{})string { switch x := x.(type) { casenil: return"NULL" caseint, uint: return fmt.Sprintf("%d", x) // x has type interface{} here. casebool: if x { return"TRUE" } return"FALSE" casestring: return sqlQuoteString(x) // (not shown) default: panic(fmt.Sprintf("unexpected type %T: %v", x, x)) } }