阅读论文 MapReduce,做个总结,部分内容参考课程的笔记。
概念
MapReduce 是一个编程模型,用于处理和生成大型数据集。它将并行、容错、数据分布和负载均衡的复杂性隐藏在库中,使得没有任何并行和分布式系统经验的程序员可以轻松利用大型分布式系统的资源。
MapReduce 将计算(computation)抽象为 \(Map\) 和 \(Reduce\) 函数。通常,\(Map\) 函数处理一个键值对,生成一组中间键值对。然后 MapReduce 库将具有相同中间键的值存储在一个列表中,以迭代器的方式提供给 \(Reduce\) 函数,避免因为数据量太大从而溢出到磁盘。\(Reduce\) 函数处理一个中间键以及该键的值列表,然后将列表中的值合并。
以下是可以被抽象为 MapReduce 计算的问题:统计文档中单词的出现次数,Grep(模式匹配),倒排索引,排序等。
实现
MapReduce 的实现方式取决于使用场景,Google 的常见计算场景是通过交换式以太网连接的大型计算机集群,使用 GFS 管理存储在各个机器的磁盘上的数据。用户将作业(job)提交给调度系统,每个作业由多个任务(task)组成,通过调度系统映射到可用的机器上。有关场景的详细信息见论文,下面介绍基于该场景的 MapReduce 实现。
概述
用户程序在调用 \(MapReduce\) 函数之后,用户程序中的 MapReduce 库首先将输入文件划分为 \(M\) 块,通常每块 16-64 MB。然后将用户程序复制到集群的多个机器上运行,由一个 master 和多个 worker 组成,master 会将一个 map 任务或 reduce 任务分配给空闲的 worker。
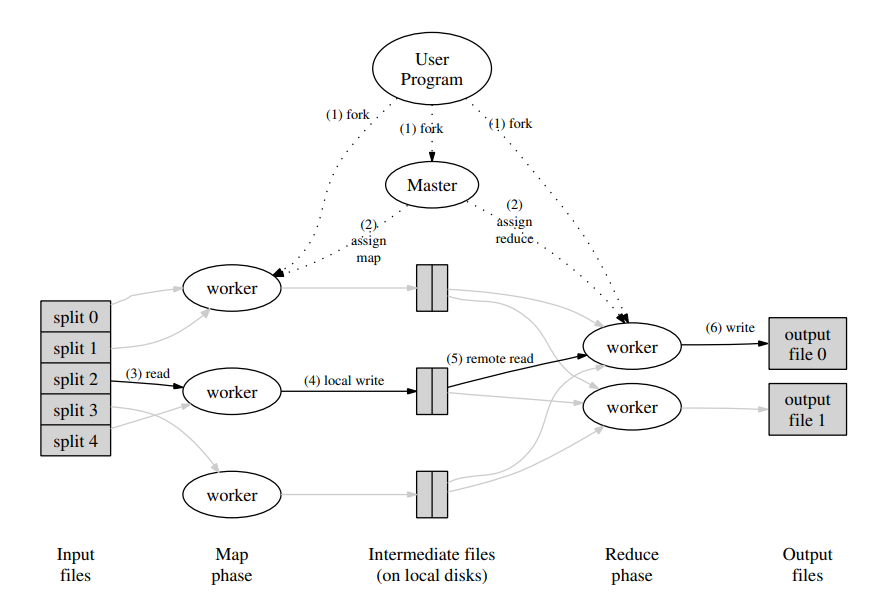
GFS 将所有文件划分为 64 MB 的块,并且将每个块的多个副本存储在不同的机器上。MapReduce 的 master 将 map 任务分配给包含输入文件的机器,从而可以避免通过网络传输输入数据(节省网络带宽)。
map worker 从 GFS 中读取文件,解析键值对并将其传递给用户的 \(Map\) 函数。\(Map\) 函数生成的中间键值对会被分区函数划分为 \(R\) 个文件(每个 reduce 任务一个文件),存储在机器的本地磁盘。\(R\) 个中间文件的位置和大小信息会被发送给 master,然后 master 负责将这些信息发送给 reduce worker。
reduce worker 收到文件的位置和大小信息之后,使用远程过程调用(RPC)从 map worker 的磁盘读取文件。当 reduce worker 读取完 \(M\) 个中间文件时,它会将数据按照中间键排序,以使相同键的键值对彼此相邻。reduce worker 迭代已排序的数据,它将唯一键以及该键对应的值列表传递给用户的 \(Reduce\) 函数。\(Reduce\) 函数合并数据,将结果写入 GFS 中的一个文件(每个 reduce 任务一个文件)。PS:GFS 会将输出文件以多个副本块的形式存储在多个机器上。
当所有 map 和 reduce 任务完成之后,master 唤醒用户程序。此时,在用户程序中的 \(MapReduce\) 函数调用返回至用户代码。通常,用户不需要将这些文件合并,而是将这些文件作为另一个 MapReduce 作业的输入。
细节
Master 数据结构
对于每个 map 和 reduce 任务,master 会记录任务的状态(idle,in-progress,completed),以及非 idle 任务所在的 worker 的标识。对于每个 map 任务,master 会记录 \(R\) 个中间文件的位置和大小信息,总共记录 \(M\times R\) 个信息。
容错
worker 失效
master 定期对每个 worker 执行 ping 操作,如果超时未响应则将其标记为失效。失效 worker 已完成的任何 map 任务、正在执行的 map 和 reduce 任务都会被重置为 idle 状态,从而可以分配给其他 worker。
已完成的 map 任务在 map worker 发生故障时需要重新执行,因为它们的输出存储在失效机器的本地磁盘上,无法被访问。而已完成的 reduce 任务将输出存储在 GFS 中,所以在发生故障时不需要重新执行。
当失效的 map worker A 被 map worker B 替代时,将会通知所有 reduce worker 重新执行,任何没有从 A 读取数据的 reduce 任务将会从 B 读取数据。PS:已从 A 读取数据的 reduce 任务该如何处理,论文没有说明。我的想法是,如果已读取完,则不会有问题。如果读取到一半,那么直接丢弃即可。
master 失效
定期持久化 master 数据结构的检查点(checkpoint),如果 master 失效,则可以从上一个检查点状态重新开始。论文中表示单个 master 失效的可能性不大,所以发生故障时会中止 MapReduce 计算。
PS:检查点和失效点之间的状态会丢失,有可能已完成的 map 任务没有被 master 持久记录已完成。如果持久状态是 idle,则会导致重新分配 map 任务。如果持久状态是 in-progress,则需要等待 worker 发送完成信息,但 worker 如何知道需要重新发送完成信息,这需要额外的机制。
任务粒度
一个 map 任务处理一个文件,生成 \(R\) 个中间文件,分别由 \(R\) 个 reduce 任务处理。理论上,\(M\) 和 \(R\) 的大小应该远大于 worker 的数量,从而分配更多的任务给较快的机器,以均衡负载。如果 worker 发生故障,还可以通过将任务分散到多个 worker 上来提升故障恢复的速度。
备份任务
由于 MapReduce 操作需要等待所有任务完成才能够继续推进,所以少数缓慢的机器(straggler)会拖慢整个操作。当 MapReduce 操作接近完成时,master 可以冗余执行剩余的任务,以缩短 MapReduce 的执行时间。
问题
Q:如果网络延迟导致 master 将 worker 标记为失效,master 如何处理旧 map worker 发送的中间文件信息?GFS 如何处理重复 reduce 任务的输出?
A:对于 map 任务,论文提到 master 会忽略 map 任务的重复完成消息,但是它是否会接收旧 worker 的消息,毕竟已经分配新 worker 重新执行该 map 任务。不论如何,只要保证 reduce 任务只从其中一个中间文件读取数据,就没有问题。对于 reduce 任务,输出首先被写入临时文件,当任务完成时再重命名为最终文件,GFS 提供原子重命名(使用锁),从而相同 reduce 任务只会有一个输出文件。
总结
论文在介绍完实现之后,还提出对实现的改进、测试实现在 Grep 和 Sort 场景的性能等。MapReduce 的成功主要在于,隐藏各种细节使得 MapReduce 易于使用,很多问题都可以表示为 MapReduce 计算,而且作者开发的 MapReduce 实现可以有效利用大型计算机集群的资源。从中可以学到:限制编程模型可以使并行和分布式计算更容易,使计算具有容错性;网络带宽是稀缺资源,使用局部性优化可以节省网络带宽;冗余执行可以减少缓慢机器的影响。