参考 mini-lsm,Discord,Rust Documentation,Tour of Rust。
Week 1 Overview: Mini-LSM
Memtables
如果要在内存中存储键值对,可以简单的使用哈希表,但是如果要支持顺序遍历以及范围查询,要使用特殊的数据结构,例如跳表、B/B+ 树、红黑树、AVL树等。为什么 LSM 实现使用跳表(crossbeam_skiplist)作为内存表的数据结构? B/B+ 树主要是针对磁盘 I/O 做优化,插入/删除会涉及页分裂和合并,在纯内存的场景下不太适用。红黑树是近似平衡的,AVL 树是严格平衡的,所以红黑树的插入/删除效率更好,而 AVL 树的查找效率更好。跳表的实现更加简单,而且并发友好,只需要锁定局部数据。不过跳表是基于链表实现的,数据局部性可能较差,而且概率数据结构稳定性也会差点。
为什么内存表在 delete 时只是将值置为空,而不是删除整个键值对? 因为如果当前内存表找不到指定的 Key,那么会继续在已经冻结的内存表中找,如果删除整个键值对,则会丢失该删除操作。为什么要有多个内存表呢? 当前内存表执行 get/put 操作的同时,可以基于冻结的内存表构建 SST,然后刷到磁盘中,而不会 STW 阻塞整个 LSM。
何时使用 state 读写锁和 state_lock 独占锁? 由于使用的跳表是支持无锁并发的,读写跳表只需要加 state 读锁,但是判断是否冻结以及整个冻结操作都需要加 state_lock 独占锁来保证原子性,可以使用双重检查加锁来优化性能。然后冻结操作内会加 state 写锁,将当前内存表加入冻结列表,然后创建一个新的内存表。在内存表超出限制大小需要冻结时,将 state 读锁释放再加写锁,与直接将读锁升级为写锁有什么区别? 在释放读锁之后,依然允许其他线程执行 get/put 操作,此时当前冻结线程可以执行昂贵的磁盘 I/O 而不会影响整体的性能。
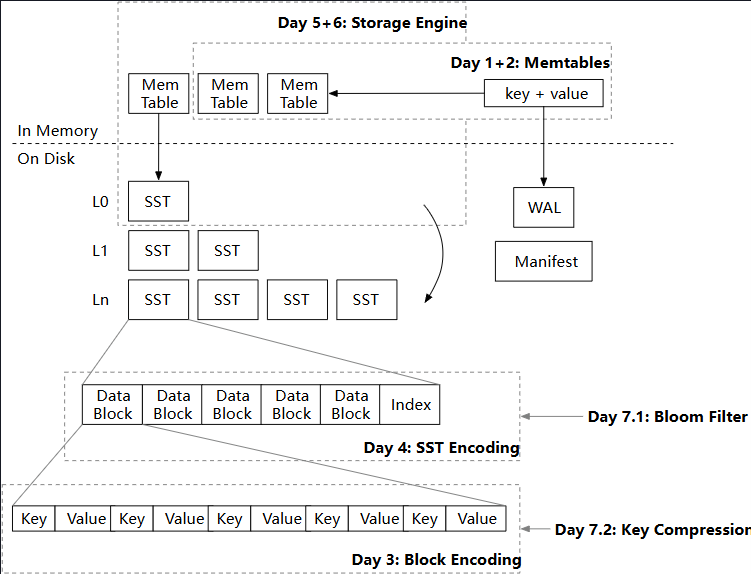
Merge Iterator
可以构建迭代器来遍历内存表,像是 Java 中的迭代器通常会有 hasNext() 和 next() 方法来判断迭代器的有效性以及获取下一个元素。StorageIterator 迭代器的设计有点不同,next() 只会移动内部的跳表迭代器而不会返回元素,获取元素是通过 key() 和 value() 方法实现的。为什么 StorageIterator 迭代器的设计和 Rust 风格的迭代器不同?为什么 MemTableIterator 需要自引用? 因为 StorageIterator 迭代器可能需要多次获取当前 Key 而不移动到下一个元素,所以将移动操作和取值操作分离是比较好的选择。使用自引用结构的目的是避免编写 Rust 的生命周期代码的复杂性。
实现单个内存表迭代器之后,因为除当前内存表外还有多个冻结内存表,所以需要一个合并迭代器,将所有内存表迭代器合并,从而实现顺序遍历。如果有多个内存表包含相同的键,需要返回该键的最新值,以及跳过其他包含旧值的键。可以使用堆来对多个迭代器排序,首先按照键的大小排序,然后按照内存表的新旧编号排序。
1 | iter1: b->del, c->4, d->5 |
1 | a->1, b->del, c->4, d->5, e->4 |
Rust 的 BinaryHeap 在修改堆中元素之后,会自动排序保证堆的有效性。如果在修改之后迭代器报错,不能直接返回错误信息,而要首先从堆中移除失效的迭代器,从而避免访问失效的迭代器(会调用其方法获取 Key)。
1 | let Some(mut inner_iter) = self.iters.peek_mut() { |
实现合并迭代器 MergeIterator 之后,外部还有一个 LsmIterator 做包装,用来过滤被逻辑删除的键,也就是在遍历时会自动跳过值为空的键。然后 LsmIterator 外部又有一个 FusedIterator 做包装,在底层迭代器报错之后,会避免再次访问底层迭代器。为什么不直接在 MemTableIterator 中过滤被逻辑删除的键? 在合并迭代器时需要知道该键在新内存表被删除避免读取到旧内存表的值。
Block
当内存表数量超过系统限制时,会将内存表作为 SST 刷新到磁盘,一个 SST 由多个块组成,单个块的大小通常是 4KB。编码方式如下:键值对是变长编码,作为 Entry 存储在 Data Section,同时维护每个 Entry 的偏移量来支持二分查找,最后存储总的 Entry 数量从而支持定位 Offset Section 的起始位置。
1 | ---------------------------------------------------------------------------------------------------- |
1 | ----------------------------------------------------------------------- |
Sorted String Table (SST)
SST 由存储在磁盘上的数据块和索引块组成,数据块是按需加载的,只有在用户请求时才会加载到内存中。索引块也可以按需加载,但在本项目中假设所有 SST 索引块(元数据块)都能装入内存。一个 SST 文件的大小通常是 256MB,在构建 SST 时最好预分配 Vec 的空间,避免频繁动态扩容的开销。 如果单个数据块的大小超出限制,会自动创建一个新块存储数据。SST 的元数据包括,每个数据块的第一个和最后一个键以及该数据块的偏移量。最后存储元数据的偏移量从而支持定位元数据的起始位置。
1 | ------------------------------------------------------------------------------------------- |
在实现 SsTableIterator 的 seek_to_key 方法时(找到第一个 ? >= x 的键),可以根据数据块的第一个键使用二分查找来快速定位目标数据块。需要注意的是,如果目标 Key 是 x,要找的是最后一个满足 first_key <= x 的数据块,而且在调用该 BlockIterator 的 seek_to_key 方法之后,还要额外判断该 BlockIterator 是否失效。例如,查找 b 会定位到第一个数据块(正确),而查找 d 也会定位到第一个数据块(错误),然后在 BlockIterator 上调用 seek_to_key 会导致迭代器失效,此时需要跳到下一个块上,也就是说第二个数据块才是目标块。
1 | -------------------------------------- |
可以使用缓存来加速数据块的访问,项目使用 moka-rs 作为缓存库来实现块缓存,块由 (sst_id, block_id) 唯一标识。
Read Path & Write Path
实现完成内存表和 SST 结构之后,可以实现 TwoMergeIterator 来合并两者的迭代器,理论上可以直接使用之前实现的 MergeIterator,不过这里只有两个迭代器需要合并,所以这里使用一个更简单的实现。然后可以修改 LsmStorageInner 的 scan 和 get 方法的实现,将 SST 添加到读取路径中。由于创建 SST 的迭代器会比较耗时(涉及磁盘 I/O),所以不要在整个过程持有 state 读锁,而是创建一个 state 快照,然后基于快照创建迭代器来访问数据。
创建 SST 的合并迭代器需要加载所有底层 SST 的第一个块,优化方式是并行创建迭代器。在 LsmStorageInner::scan 方法中,实际上可以利用参数 lower 和 upper,以及 SST 的 first_key 和 last_key 来过滤 SST,避免不必要的磁盘 I/O。当内存表的数量达到上限时,需要将最旧的冻结内存表以 SST 文件的形式刷到磁盘,刷新工作主要由后台线程负责。
1 | let snapshot = { |
Snack Time: SST Optimizations
可以在读取路径上集成布隆过滤器来过滤 SST,布隆过滤器基于 SST 包含的数据创建,每个 SST 都包含一个持久化的布隆过滤器数据。由于数据块中的键是有序存储的,可以对键进行前缀压缩。根据相邻键进行键前缀压缩而不是根据块中的第一个键进行压缩有哪些优点/缺点? 项目中是根据数据块的 first_key 的前缀进行压缩,这样可以在查找时快速复原当前 Key。如果是根据相邻键压缩,那么压缩比例会更高,但是压缩和复原最坏需要遍历所有前缀数据。
1 | ----------------------------------------------------------------------------------------------------- |
1 | key_overlap_len (u16) | rest_key_len (u16) | key (rest_key_len) |
Week 2 Overview: Compaction and Persistence
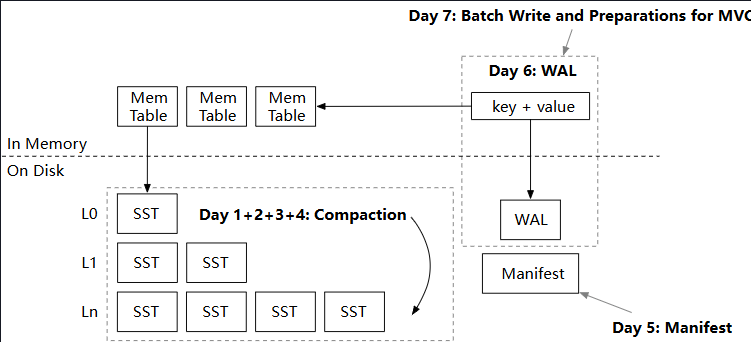
Compaction Implementation
可以对 L0 SST 文件进行压缩,避免读放大,由于各个 SST 之间的键范围存在重叠。最简单的方式是进行 Full Compaction,将所有键按顺序排序存储到一组新的 SST 中(被称为 sorted run)。压缩时允许并行执行读写操作,所以不持有 state 的读写锁,依然复制状态快照(不会复制 SST,只是复制状态),然后基于快照创建 L0 和 L1(之前压缩的 L1 需要和 L0 再次整合)的合并迭代器。
使用 SsTableBuilder 构建 SST,如果超出大小限制则拆分文件,在迭代时过滤已经被删除的键,重复的键已经在合并迭代器内部过滤。替换状态时只需要持有 state_lock 独占锁,state 读写锁依然只在复制状态快照时持有,允许并行执行读写内存表的操作。替换状态不会丢失内存表的修改,因为状态只包含内存表的指针。
由于在压缩时也会产生 L0 SST 文件,所以在替换状态时只删除被压缩的 L0 SST 文件、以及所有 L1 SST 文件。在 macOS/Linux 操作系统上,直接删除文件不会有问题,即使可能存在并行读取,因为操作系统只有在没有文件句柄被持有时才会真正删除该文件。在 Windows 上似乎会直接报错。 删除文件操作在解锁 state_lock 之后执行。
Simple Compaction Strategy
实现 Simple Leveled Compaction 策略,基本想法是指定一个最大层数 max_levels(不包括 L0),然后在 L0 SST 文件数量达到阈值,或者下层文件数量和上层(>= L1)文件数量的比值小于阈值时执行相邻层级之间的压缩。是否可以像 Full Compaction 一样直接过滤已经被删除的键? 只有当压缩 Level 是最底层时,才能过滤掉已经被删除的键,否则可能读取到下层 Level 的旧值。主动选择旧 Level 进行压缩,即使其没有达到指定阈值,是否是一个好主意? 参考 Lethe 文章,定期压缩可以减少无效键导致的空间放大、压缩无效键导致的写放大、无效键占用布隆过滤器导致误报率提升。
Tiered Compaction Strategy
实现 Tiered Compaction 策略(RocksDB 的 Universal Compaction),该压缩不会使用 L0,所有 SST 都直接存放到 levels 中,压缩过程中生成的 SST 总是会占据一个 tier,tier 的编号就是该 tier 包含的第一个 SST ID。
首先,只有当 tier 的数量超过阈值才会触发压缩。当估计的空间放大率 all levels except last level size / last level size 超过阈值会触发 Full Compaction,或者 this tier size / sum of all previous tiers size 超过阈值会触发前缀压缩。如果没有触发上述压缩,则会直接触发前缀压缩,压缩的最大层数由参数限制。由于压缩过程中也会生成 SST,所以修改状态时替换的是 levels 的中间部分而不一定是前缀。
Leveled Compaction Strategy
实现 Leveled Compaction 策略,相当于对 Simple Leveled Compaction 的优化。之前的策略会在相邻层级之间压缩数据,初始时会反复地将上层数据压缩到下面的空层中,更好的策略是跳过中间的空层,直接和有数据的低层进行压缩。在数据量不是很大的时候,没有必要分层压缩产生读放大,所以给最底层设置一个阈值 base_level_size_mb,在最底层的文件大小超过该阈值之前总是将数据压缩到最底层。
然后使用 level_size_multiplier 来确定各个层级的 target size,只允许有一个小于 base_level_size_mb 的正 target size,该层记作 base level。每次压缩 L0 的数据都直接压缩到 base level,这样可以确保在数据量比较小时使用较少的层级(后缀层级),避免较多层级产生读放大、以及反复压缩相邻空层产生写放大。
优先将满足 current_size / target_size > 1.0 的比值最大的层级压缩到下层中,尽量减少空间放大。之前的策略总是将上层所有 SST 和下层做压缩,这样压缩过程中的空间放大会比较多。可以实现部分压缩,从上层选择最旧的 SST,然后和下层键范围重叠的 SST 做压缩。对于 L0 可以计算整个 L0 的最小最大键,然后和下层范围重叠的 SST 做压缩。需要考虑没有重叠的情况,此时压缩结果需要放在 Level 的开头或者末尾,比较简单的实现方式就是根据 SST 的 first_key 排序。
Manifest
可以持久化 LSM 存储引擎的状态,从而允许重启时恢复。简单的方法是,在状态被修改时将所有状态持久化,但是这样磁盘 I/O 开销较大,特别是修改操作比较频繁时。该项目使用 Manifest 文件维护 SST Flush 和 Compaction 操作记录,SST Flush 操作记录该 SST 的 sst_id,Compaction 操作记录压缩任务 task 和压缩结果 output。在不持有 state 读写锁时追加 Manifest 文件,允许并行读写内存表。
1 | | JSON record | JSON record | JSON record | JSON record | |
由于记录的信息有限,在重启恢复时只能先构建 L0 和 levels 元数据,然后根据这些元数据读取磁盘上的 SST 来构建 sstables 哈希表。如果在压缩过程中使用到 sstables 中 SST 的 first_key 排序,那么在恢复时需要特殊处理。不能在应用记录的过程中构建 sstables,因为记录中的 SST 可能已经被压缩,从而对应的文件已经从磁盘删除。
为保证磁盘中 SST 和 Manifest 文件的一致性,需要在追加 Manifest 文件之前 Sync 整个存储目录,或者可以在修改文件之后总是执行 Sync。 在关闭 LSM 之前,需要将所有内存表刷新到 SST 中。在恢复时需要维护最大的 max_sst_id,恢复完成之后需要根据 max_sst_id + 1 创建当前的内存表。由于 Manifest 文件会记录所有操作,所以需要定时创建快照来截断日志(例如 Raft 中状态机快照),来减少空间占用以及加快恢复速度。
Write-Ahead Log (WAL)
Manifest 文件可以保证正常关闭时,LSM 状态的持久性,但是如果发生崩溃,就需要依靠 WAL 来保证持久性。每个内存表对应一个 WAL 文件,如果冻结内存表被刷新到 SST 文件中,则可以将 WAL 文件删除,前提是该 SST 文件已经被 Sync 到磁盘中(默认在创建 SST 时就会 Sync)。
1 | | key_len | key | value_len | value | |
为了能够在重启时恢复内存表,需要在 Manifest 文件中维护 NewMemtable 记录,该记录存储内存表的 ID。为减少磁盘 I/O 以及系统调用开销,可以在将当前内存表转移到冻结内存表时刷新 WAL 到磁盘,而不是在每次修改内存表时刷新,不过如果宕机则会丢失当前内存表的数据。创建 WAL 文件应该在追加 Manifest 记录之前,这样可以保证恢复时的一致性。在重启恢复时,依然不能在应用记录的过程中读取 WAL,因为记录中的 WAL 可能已经被删除,由于该内存表已经被刷新到 SST 中。
Snack Time: Batch Write and Checksums
实现批量写入接口,允许用户提供一组 put 和 delete 操作批量执行。给 Block、SST Meta(Block Meta、Bloom Filter)、WAL 以及 Manifest 文件添加校验和,从而允许检查数据是否损坏。
1 | --------------------------------------------------------------------------------------------------------------------------- |
1 | ---------------------------------------------------------------------------------------------------------- |
1 | | key_len | key | value_len | value | checksum | |
1 | | len | JSON record | checksum | len | JSON record | checksum | len | JSON record | checksum | |
Week 3 Overview: Multi-Version Concurrency Control
Timestamp Key Encoding + Refactor
Snapshot Read - Memtables and Timestamps
Snapshot Read - Engine Read Path and Transaction API
为实现 MVCC 需要重构代码,首先替换 Key 的表示以包含时间戳字段,按照 user_key 升序 ts 降序排序,这样可以优先读到新版本的数据。然后修改内存表、Block、SST、WAL 以支持时间戳字段,在重启恢复 LSM 状态时需要根据 SST 和内存表中使用的最大时间戳来确定当前时间戳。在整个 write_batch 中需要持有 MVCC 的 write_lock,从而确保按照时间戳递增的顺序执行写入操作(只有写入操作会递增时间戳)。
1 | Alternative key representation: | user_key (varlen) | ts (8 bytes) | in a single slice |
1 | key_overlap_len (u16) | remaining_key_len (u16) | key (remaining_key_len) | timestamp (u64) |
1 | | key_len (exclude ts len) (u16) | key | ts (u64) | value_len (u16) | value | checksum (u32) | |
在压缩过程中,暂时忽略 compact_to_bottom_level 保留所有版本的数据(不执行实际的删除操作)。确保不同时间戳的相同 user_key 在同一个的 SST 中,即使超出 SST 的大小限制,从而简化其他功能的开发。个人认为主要是 Leveled Compaction 会从上层部分压缩到下层,如果多个版本不在一个 SST 中,会存在旧版本的键值对在上层而新版本的键值对被压缩到下层的情况。修改 LsmIterator 包含时间戳字段,只迭代 <= 当前时间戳的最新数据,如果键被删除就跳过该键的所有旧版本。应该首先判断版本再判断删除,因为删除操作可能是在快照之后的版本执行的。
在 get 读取路径中,只需要根据当前时间戳创建事务,读取快照内可见的数据即可。不过由于内存表会包含多个版本的数据,所以只能使用范围查询来查找该 user_key 的最新可见版本。在 scan 读取路径中,如果 lower 和 upper 是 Bound::Included,则对应的时间戳是 ts 和 TS_RANGE_END。如果是 Bound::Excluded,则对应的时间戳是 TS_RANGE_END 和 ts | TS_RANGE_BEGIN。因为对于 lower 而言,必须定位到对应 user_key_begin 的最旧版本,才能确保迭代器跳过该 user_key_begin。对于 upper 而言,必须定位到 ts 及更新的版本才能确保迭代器跳过该 user_key_end。
Watermark and Garbage Collection
Watermark 是维护系统中 lowest_read_ts 的结构,可以在创建/终止事务时,使用 BTreeMap 维护各个时间戳的引用计数来实现。然后压缩操作保留所有键的最新快照以及所有 >= lowest_read_ts 的快照,例外情况是如果当前压缩到 compact_to_bottom_level,且键的最新快照是删除操作,且该快照 <= lowest_read_ts,则不保留该键值对到新 SST 中。
Transaction and Optimistic Concurrency Control
事务内执行的修改操作都存储到事务的 local_storage 本地内存表中,该表不包含时间戳信息。读取操作会先读取本地内存表,再读取公共内存表及 SST 文件。本地内存表迭代器 TxnLocalIterator 和之前没有时间戳的公共内存表实现相同,而 TxnIterator 会使用 TwoMergeIterator 合并本地和公共数据,不过需要跳过被删除的键,由于之前只有 LsmIterator 会执行该逻辑。
提交事务会将当前事务的状态设置为已提交,然后将本地内存表的数据通过 LsmStorageInner::write_batch 批量提交到公共内存表中。如果在写入公共内存表的过程中崩溃,恢复时的 WAL 无法区分事务之间的边界,从而不能保证事务的原子性。可以实现批量 WAL,将事务内的写入操作批量提交给 WAL,然后添加 Header 和 Footer 来区分事务边界。而且要保证批量写入操作都存储到相同的内存表中,从而使得事务内的批量操作只存储在一个 WAL 文件中。
1 | | HEADER | BODY | FOOTER | |
(A Partial) Serializable Snapshot Isolation
在事务内执行读写操作时维护读写集,然后在提交时验证当前事务是否和已提交事务冲突(OCC),从而实现可串行化快照隔离。首先,需要确保验证、提交操作的原子性,所以在 commit 方法开始时持有 MVCC 的 commit_lock 锁。然后遍历在 (read_ts, expected_commit_ts) 范围内提交的事务,判断当前事务的读集是否和这些事务的写集重叠。如果重叠则说明当前事务和已提交事务冲突,直接返回错误信息。例外情况是,如果当前事务是只读的,则不需要验证冲突。基本想法是,写操作会基于读操作的结果执行,而只读则不会修改公共数据。
在本项目中,对于 scan 操作只将扫描到的键加入读集而不是扫描范围,这样实现简单但是无法真正保证可串行化快照隔离(依然存在 write skew 异常)。在读写集中存储的是键的哈希值,这样可以减少内存空间占用、加快验证速度,但是会存在哈希冲突导致误报。在提交事务时可以将提交时间戳小于 lowest_read_ts 的已提交事务数据移除,然后将当前事务数据加入已提交事务集合。
1 | txn1: len(scan(..)) = 2 |
Snack Time: Compaction Filters
如果需要删除以某个字符串为前缀的所有键,正常调用删除方法不但不会减少空间占用,反而会为每个键新增一个删除版本,只有压缩到最底层才会真正删除。可以使用压缩过滤器,添加前缀匹配规则到压缩过滤器,然后在压缩过程中不保留匹配的键值对到 SST 中。不过保证正确的前提是,所有事务都不会读取相关的键。