系统概述
编译系统

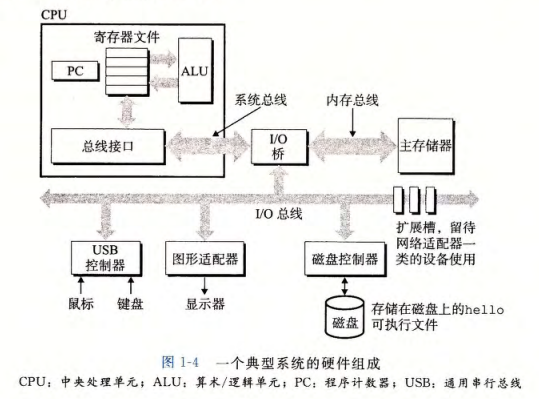
系统硬件
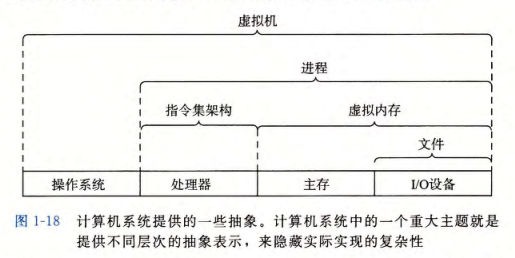
系统抽象
信息存储
基本概念
大多数计算机使用 8 位的块,或者字节(byte),作为最小的可寻址的内存单位,而不是访问内存中单独的位。机器级程序将内存视为一个非常大的字节数组,称为虚拟内存(virtual memory)。内存的每个字节都由一个唯一的数字来标识,称为它的地址(address),所有可能地址的集合就称为虚拟地址空间(virtual address space)。
每台计算机都有一个字长(word size),指明指针数据的标称大小(nominal size)。因为虚拟地址是以这样的一个字来编码的,所以字长决定的最重要的系统参数就是虚拟地址空间的最大大小。也就是说,对于一个字长为 \(w\) 位的机器而言,虚拟地址的范围为 0 ~ \(2^{w}\)-1,程序最多访问 \(2^{w}\) 个字节。
我们将程序称为“32 位程序”或“64 位程序”时,区别在于该程序是如何编译的,而不是其运行的机器类型。
字节顺序
对于跨越多字节的程序对象,我们必须建立两个规则:这个对象的地址是什么,以及在内存中如何排列这些字节。
在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。例如,假设一个类型为 int 的变量 × 的地址为 0x100,也就是说,地址表达式 &× 的值为 0x100。那么,(假设数据类型 int 为 32 位表示)x 的 4 个字节将被存储在内存的 0x100、0x101、0x102 和 0x103 位置。
在内存中按照从最低有效字节到最高有效字节的顺序存储对象的方式,称为小端法(little endian)。按照从最高有效字节到最低有效字节的顺序存储对象的方式,称为大端法(big endian)。假设变量 x 的类型为 int,位于地址 0x100 处,它的十六进制值为 0x01234567。地址范围 0x100 ~ 0x103 的字节顺序依赖于机器的类型:

整数表示
编码方式
对向量 \(\vec{x}=[x_{w-1},x_{w-2},\cdots,x_{0}]\),各编码方式的定义如下:
| 编码方式 | 定义 |
|---|---|
| 无符号数 | \(B2U_{w}(\vec{x})\dot =\sum_{i=0}^{w-1}x_{i}2^{i}\) |
| 补码 | \(B2T_{w}(\vec{x})\dot =-x_{w-1}2^{w-1}+\sum_{i=0}^{w-2}x_{i}2^{i}\) |
| 反码 | \(B2O_{w}(\vec{x})\dot =-x_{w-1}(2^{w-1}-1)+\sum_{i=0}^{w-2}x_{i}2^{i}\) |
| 原码 | \(B2S_{w}(\vec{x})\dot =(-1)^{x_{w-1}}\cdot(\sum_{i=0}^{w-2}x_{i}2^{i})\) |
转换规则
对于大多数C语言的实现,处理同样字长的有符号数和无符号数之间相互转换的一般规则是:数值可能会改变,但是位模式不变。转换关系如下:
- 补码转换为无符号数,\(T2U_{w}(x)=x+x_{w-1}2^{w}\)。
- 无符号数转换为补码,\(U2T_{w}(u)=u-u_{w-1}2^{w}\)。
当执行一个运算时,如果它的一个运算数是有符号的而另一个是无符号的,那么 C 语言会隐式地将有符号参数强制类型转换为无符号数,并假设这两个数都是非负的,来执行这个运算。
扩展规则
要将一个无符号数转换为一个更大的数据类型,我们只要简单地在表示的开头添加 0,这种运算被称为零扩展(zero extension)。要将一个补码数字转换为一个更大的数据类型,可以执行一个符号扩展(sign extension),在表示中添加最高有效位的值。对于扩展大小和转换符号的顺序,C 语言标准要求,先扩展大小,再转换符号。
运算规则
- 检测无符号数加法中的溢出:对满足 \(0\leq x,y\leq UMax_{w}\) 的 \(x\) 和 \(y\),令 \(s\dot=x+_{w}^{u}y\)。当且仅当 \(s<x\)(或者等价地 \(s<y\))时,计算 \(s\) 发生溢出。
- 检测补码数字加法中的溢出:对满足 \(TMin_{w}\leq x,y\leq TMax_{w}\) 的 \(x\) 和 \(y\),令 \(s\dot=x+_{w}^{t}y\)。当且仅当 \(x>0\),\(y>0\),但 \(s\leq 0\) 时,计算 \(s\) 发生正溢出。当且仅当 \(x<0\),\(y<0\),但 \(s\geq 0\) 时,计算 \(s\) 发生负溢出。
计算一个位级表示的值的在补码加法下的逆元:第一种方法是对每一位取反,再对结果加 1,即 -x == ~x + 1;第二种方法是将最低位的 1 左侧的所有位取反。
无符号乘法和补码乘法在截断之后的位级表示是相同的,该结论可以通过公式推导得出。
整数乘法运算指令比其他整数运算(例如加法、减法、移位)更慢,因此编译器会尝试使用移位和加减法的组合来代替乘以常数因子的乘法。是否实际替换,取决于两种方案的相对速度。
整数除法总是向零取整,即对于正数向下取整,对于负数向上取整。当使用移位运算替换除以 2 的幂的除法时,需要注意补码移位是向下取整。也就是说,对于负数需要添加“偏置(biasing)”值,从而使得其向零取整。如下所示:
1 | x / (1 << k) == (x < 0 ? x + (1 << k) - 1 : x) >> k |
浮点标准
IEEE 浮点标准用 \(V=(-1)^{s}\times M\times 2^{E}\) 的形式来表示一个数:
-
符号(sign) \(s\) 决定这数是负数(\(s=1\))还是正数(\(s=0\)),而对于数值 0 的符号位解释作为特殊情况处理。
-
尾数(significand) \(M\) 是一个二进制小数,它的范围是1 ~ \(2-\varepsilon\),或者是 0 ~ \(1-\varepsilon\)。
-
阶码(exponent) \(E\) 的作用是对浮点数加权,这个权重是 2 的 \(E\) 次幂(可能是负数)。
将浮点数的位表示划分为三个字段,分别对这些值进行编码:
- 一个单独的符号位 \(s\) 直接编码符号 \(s\)。
- \(k\) 位的阶码字段 \(exp=e_{k-1}\cdots e_{1}e_{0}\) 编码阶码 \(E\)。
- \(n\) 位小数字段 \(frac=f_{n-1}\cdots f_{1}f_{0}\),编码尾数 \(M\),但是编码出来的值也依赖于阶码字段的值是否等于 0。
图 2-32 给出了将这三个字段装进字中两种最常见的格式。在单精度浮点格式中,s、exp 和 frac 字段分别为 1 位、k = 8 位和 n = 23 位,得到一个 32 位的表示。在双精度浮点格式中,s、exp 和 frac 字段分别为 1 位、k = 11 位和 n = 52 位,得到一个 64 位的表示。

给定位表示,根据 exp 的值,被编码的值可以分成三种不同的情况。
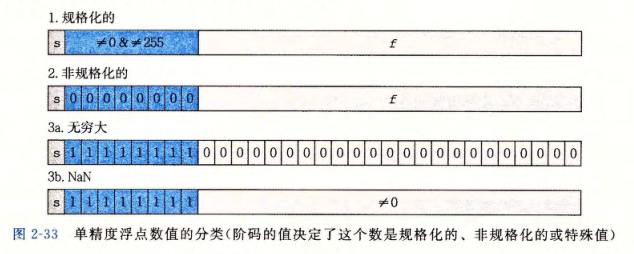
| 分类 | 阶码 | 尾数 |
|---|---|---|
| 规格化的值 | \(E=e-Bias\),\(Bias=2^{k-1}-1\) | \(M=1+f\) |
| 非规格化的值 | \(E=1-Bias\) | \(M=f\) |
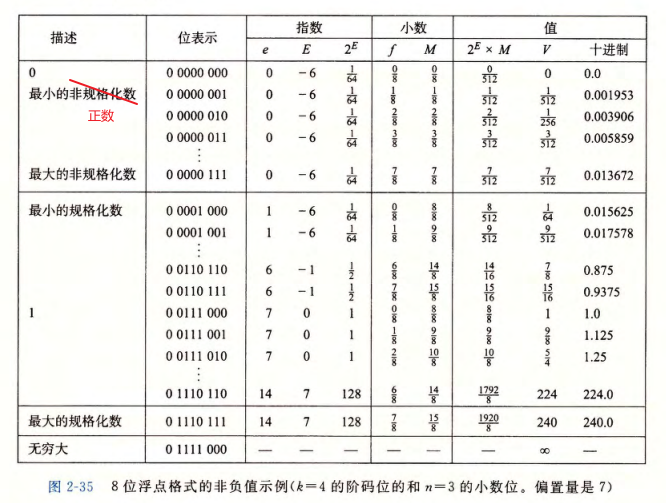
这种表示具有一个有趣的属性,假如我们将图 2-35 中的值的位表达式解释为无符号整数,它们就是按升序排列的,就像它们表示的浮点数一样。IEEE 格式如此设计就是为了浮点数能够使用整数排序函数来进行排序。当处理负数时,有一个小的难点,因为它们有开头的 1,并且它们是按照降序出现的,但是不需要浮点运算来进行比较也能解决这个问题。
IEEE 浮点格式定义了四种不同的舍入方式:向偶数舍入(默认),向零舍入,向下舍入,向上舍入。向偶数舍入指的是,将正中间的值向偶数舍入。IEEE 标准中的浮点加法和乘法是可交换的,具有单调性,但是不可结合,不具有分配性。