参考 2PC,3PC,Oracle Transaction Manager,Seata Transaction Mode,Seata Blog(重要)。
没有时间细看各个资料和实现,以下内容掺杂个人理解,不保证正确性。 各个方案实际上就是在强一致性和可用性之间做权衡,一般保证可用性会选择最终一致性。
2PC & 3PC & XA & AT
两阶段提交分为准备和提交/回滚阶段:① 协调者向参与者发送准备请求,参与者执行操作并持久化状态,然后回复同意/拒绝。如果准备请求超时,由于某个参与者网络分区或崩溃,则协调者会直接决定中止事务。② 协调者根据参与者的回复决定提交/中止事务,只有当所有参与者都回复同意才会决定提交。协调者会将决定持久化,然后发送提交/中止请求。③ 参与者执行提交/回滚,然后回复确认。在协调者收到所有参与者的确认之后,此时可以响应客户端。否则,协调者会一直重试请求,直到参与者确认。
存在的问题:当参与者回复同意/拒绝之后,必须等待协调者做出决定,才能真正提交/回滚本地事务,期间会一直持有数据库锁。当协调者做出决定之后,必须等待所有参与者执行完成,才能响应客户端。不论是协调者还是参与者崩溃,都会阻塞整个事务。不过,某个参与者崩溃不会阻塞其他参与者的本地事务(要么提交要么回滚),由于有准备请求有超时中止机制。而协调者崩溃会阻塞所有参与者的本地事务。实际上,协调者可以使用共识算法实现容错,避免单点故障。
三阶段提交有 CanCommit、PreCommit 和 DoCommit 阶段。CanCommit 阶段只是询问参与者是否可以执行事务,而不会执行操作锁定资源,这样可以提前发现事务无法执行,避免无效的资源锁定。在 PreCommit 阶段,如果参与者回复同意,且在超时时间内没有收到协调器的提交/中止请求,则该参与者会主动提交事务(有不一致的风险)。3PC 不保证强一致性,而且相比 2PC 有额外的网络往返开销。
XA 是异构环境下实现 2PC 的工业标准,规定事务协调者和参与者通信的 API,其中异构是指参与者由不同数据库或消息队列组成。Seata 的 AT 模式从 2PC 演化而来,在准备阶段本地事务会直接提交,只不过在提交之前需要获取相关记录的全局锁,而且本地事务需要维护回滚日志表。协调器提交事务时,会让参与者异步批量删除回滚日志。回滚时参与者会根据全局和分支事务 ID 找到对应回滚日志,将日志中的后镜像数据和当前数据进行比较,根据配置的策略进行处理。AT 模式因为有全局锁,不存在脏写问题,不过默认的隔离级别是读未提交,因为读取默认不会获取全局锁,个人认为这也是它性能比 2PC 更好的原因(或许还有其他原因)。
Sega & TCC
基本概念:应用程序 AP,事务管理器 TM,资源管理器 RM,事务协调者 TC。Saga 模式没有 TCC 模式的预留操作,参与者会直接执行本地事务转移资源,存在脏写导致无法回滚的风险。例如转账场景,A 向 B 转账,如果 B 的余额增加之后,A 扣款失败,需要回滚 B 的余额,而 B 已经使用完该余额,则无法完成回滚(或者说无法完成补偿)。
TCC 表示 Try-Confirm/Cancel,有尝试阶段和确认/取消阶段。协调者请求参与者预留资源(将资源转移到中间表),如果所有资源都预留成功,则确认所有预留,否则取消所有预留。因为请求超时会重试请求,所以需要保证预留、确认和取消操作的幂等性。该方案依赖业务层实现预留、确认和取消操作,这些操作都是单独的本地事务,不存在长期持有数据库锁的问题。
操作的幂等性可以通过在数据库中维护分支事务状态表,使用全局事务 ID + 分支事务 ID 去重来实现。分支事务状态表应该存储在本地,因为要保证操作和事务状态更新的原子性,利用本地事务可以做到。不过协调者也要维护全局事务状态表,从而根据事务状态决定执行预留、确认还是取消操作。(或者有其他方案)
如果协调者请求参与者预留资源超时且重试次数耗尽,则会直接中止事务,取消所有预留的资源。如果没有预留资源的参与者收到取消预留的请求,则不会执行任何操作而是直接返回成功(空回滚)。协调者可以使用共识算法容错,根据全局事务的状态,决定预留资源或者确认/取消分支事务预留的资源。如果参与者在收到取消预留请求之后收到预留资源的请求,则会发生资源悬挂的问题。参与者在预留之前会检查该事务是否发生空回滚,如果发生则拒绝本次预留请求。
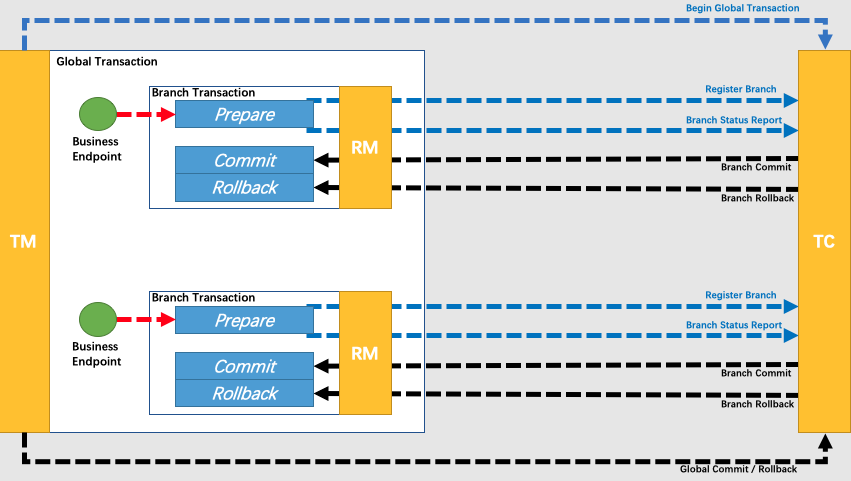
本地消息表 & 事务消息
分布式事务的问题在于,事务发起者执行本地事务之后,无法保证其他参与者的本地事务也能够执行成功。以转账为例,A 向 B 转账,A 本地执行扣款之后,向 B 发送转账请求,A 无法保证 B 执行成功,存在不一致的风险。之前的 2PC 方案是通过数据库协调来保证事务的原子性,TCC 方案是通过业务层面的设计保证全局事务的原子性。
另一种方案就是,事务发起者将待发送的请求存储到本地消息表中,和业务操作放在同一个事务中执行。然后使用定时任务定期扫描本地消息表,将待发送的消息发送给消息队列,如果发送成功则从表中删除该消息记录(或者修改状态为已发送)。事务参与者监听消息队列,拉取消息执行本地事务,然后向消息队列回复确认消费。
由于本地事务具有原子性,事务发起者可以保证业务操作执行成功时,请求消息也被记录到本地消息表。定期扫描会保证消息最终会被发送到消息队列,消息队列可以保证消息至少被消费一次,最后消费者需要再业务层面保证消费的幂等性,例如使用唯一 ID 在数据库层面去重。
注意,Kafka 保证内部的精确一次消息传递,但涉及到外部数据库就只能保证至少一次。如果需要精确一次,可以利用业务层面的幂等性做去重,也可以使用 2PC。或者利用本地事务的原子性,将日志偏移量和业务数据同时存储到数据库,然后消费者重启时读取偏移量来保证不重复消费(其实就是本地消息表方案)。
可以使用 RocketMQ 的事务消息功能实现类似本地消息表的方案。事务发起者首先向消息队列发送半消息,该消息对消费者不可见。然后发起者执行本地事务(执行业务操作 + 维护事务状态),根据本地事务的执行结果向消息队列发送提交/回滚请求,如果提交则消费者可以消费相应消息。如果发起者长时间未提交/回滚事务消息,消息队列会调用发起者提供的回查接口来查询事务状态。超时回查机制类似本地消息表的定时任务机制,目的都是保证最终一致性。事务消息方案依然需要发起者维护事务状态表,只是不需要自己使用定时任务扫描来重试请求,而是将扫描的工作交给消息队列。
不论本地消息表还是事务消息方案,如果参与者无法消费消息直到重试次数耗尽,则需要设计额外的回滚机制或者人工干预。而且和 Saga 策略类似,由于不会预留资源,存在脏写导致无法回滚的问题。这需要业务流程上做设计,保证能够通过人工干预完成事务,或者不断重试直到成功。