项目准备
项目地址:Project #0 - C++ Primer。
准备工作:创建项目仓库,学习 Git 分支,复习 C++,阅读谷歌 C++ 风格指南,学习 GDB。
Task #1 - Copy-On-Write Trie
实现
Get 函数
没有什么特别需要注意的,实现比较简单。
实现逻辑:
- 如果
root_ == nullptr为真,则返回nullptr。 - 沿着 Trie 树遍历,如果节点不存在,则返回
nullptr。 - 如果目标节点不是
TrieNodeWithValue类型,则返回nullptr。 - 否则,返回目标节点的值。
Put 函数
一开始比较疑惑的点是,智能指针存储的都是 const 修饰的节点,如果要修改就必须克隆。但是沿着树遍历的话,如果需要修改子节点,那么同样也需要让父结点指向克隆后的子节点,然后一直向上到根节点,看上去似乎使用栈比较合理。那么能不能不使用栈呢?
其实通过观察可以发现,从根节点一直到目标节点(表示字符串的节点)都是需要克隆的,如果节点存在的话。那么这样我们就可以在遍历的过程中克隆,只需要维护新克隆节点的非 const 指针就能做到。
本来想加个冗余节点减少判断的代码,但是感觉好像怎么弄都逃不过判断 key.empty() 和 root_ == nullptr。
实现逻辑:
- 如果
key.empty()为真:- 如果
root_ == nullptr为真,则使用value构造 Trie 树并返回。 - 否则,使用
root_->children_和value构造 Trie 树并返回。
- 如果
- 根据
root_ == nullptr条件初始化新 Trie 树的root。 - 沿着旧 Trie 树克隆新 Trie 树的节点(最后一个字符对应的节点需要特殊处理):
- 如果克隆完所有字符,则返回新 Trie 树。
- 否则,新 Trie 树继续创建旧 Trie 树不包含的节点,然后返回新 Trie 树。
Remove 函数
需要使用栈辅助删除,优化后代码好看多了,不像之前那么复杂(大概)。有以下几点需要注意:
① 节点不包含值需要转换为 TrieNode 类型,也就是说拷贝的时候需要调用 TrieNode::Clone()。
② 如果节点满足 children_.empty() && !is_value_node_ 条件,则需要移除该节点。一个节点的移除,可能会导致该节点的父节点也满足移除条件。移除时,记得 erase 父节点中 map 的 key。
实现逻辑:
- 如果
root_ == nullptr为真,则返回*this。 - 如果
key.empty()为真,则调用root_->TrieNode::Clone()克隆,并返回新 Trie 树。 - 沿着旧 Trie 树遍历,并将对应的节点入栈,如果节点不存在,则返回
*this。 - 将栈顶的元素依次弹出,如果当前节点需要移除,则将其移除。
- 否则,依次克隆栈中的元素,然后返回新 Trie 树。
补充
C++
因为平时用的 Java,所以有几个使用 C++ 的坑点需要注意一下。
① 使用 at 访问 const map 对象,因为 [] 运算符可能会自动添加键值。
1 | const map<int,int> m; |
② = 拷贝对象的底层结构,不像 Java 中拷贝的是对象的地址(相当于 C++ 中的指针吧)。
1 | map<int,int> m; |
③ 在 Java 中只要是对象就可以和 null 比较,而 C++ 中只有指针可以和 nullptr 比较。
GDB
① 使用 GDB 调试经常会看到 Python Exception <class ‘gdb.error’>: There is no member named _M_p,点击此处产生该问题的原因,以及相应的解决方案告诉我下载 libstdc++6-dbgsym,完美解决问题。本来不想管这个问题的,结果任务三需要在调试时打印字符串。
② 之前做 CSAPP 的二进制炸弹实验用过 GDB,可以在此查看该课程提供的 GDB 教程。以及可以阅读:GDB Tutorial: Finding Segmentation Faults。
③ 使用 GDB 调试时,最后会报错 LeakSanitizer has encountered a fatal error,因为 LeakSanitizer 不能在 GDB 下工作。不用去管这个错误,只要在不用 GDB 的情况下测试通过就行。
CMake
项目推荐使用 clang-14 作为编译器,解决方案在此。
Task #2 - Concurrent Key-Value Store
实现
因为 Trie 是写时复制的,所以似乎不需要考虑其他复杂的上锁操作,只需要简单的使用 std::mutex 即可。读操作在获取 root_ 时上锁,获取完即可解锁。写操作同理,并且需要在整个操作内对 write_lock_ 上锁。Put 时记得使用 std::move(),因为值可能是不可复制的。
补充
① 关于线程和锁的知识,推荐阅读 CS110 Lecture 10: Threads and Mutexes。
② C++ 有个复制省略(Copy elision)的优化。
③ 关于 C++ 模板的 FAQ、template 关键字的讨论 和 Dependent names 的定义。(好复杂啊)之所以查这些内容,是因为 CLion 给我生成了不同的表达式:
1 | auto value = root.template Get<T>(key); |
以我现在的理解,模板类型是根据实参推断的,如果无法推断则需要在调用时显示添加 <> 来指定类型。然后何时使用 template 没怎么弄明白。
Task #3 - Debugging
实现
挺简单的,文件 trie_debug_test.cpp 指出在 28 行打断点,但我是在 Put 时打断点调试的,应该差不多吧。
补充
无语的是,在修复上个问题时无意间下载了 gcc-12,导致在 make 时报错:/usr/bin/ld: cannot find -lstdc++: No such file or directory,问题原因以及解决方案在此。
Task #4 - SQL String Functions
实现
文件的路径:./src/include/execution/expressions 和 ./src/planner/plan_func_call.cpp。实现大小写转换比较简单,但是如果使用 std::tolower 或许有一些注意事项。注册函数时,需要保证参数是有效的,即参数只有一个并且是 VARCHAR 类型。
测试结果
就是过不去 TrieDebugger.TestCase,结果发现不是我的问题,而是因为本地的随机数和测试的随机数不同,详情见 Discord 讨论。
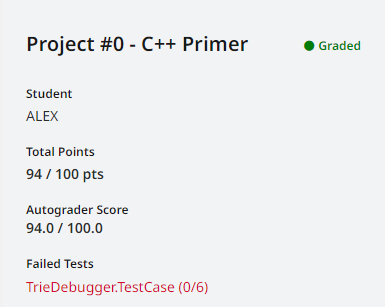
修改之后通过!

项目小结
任务一是项目的核心,主要还是把逻辑理清楚,以及注意到 key 为空串的特殊用例。一开始很多东西都不懂,查找资料学习花费了很多时间,还有就是 Debug 任务一也费了一番功夫,因为当时边界条件没弄清楚。