参考 Coroutines for Go,Coroutine Wiki。
什么是协程(coroutine)?通常使用的函数(function)也被称为子例程(subroutine),一系列调用会形成一个调用栈(call stack),调用者(caller)和被调用者(callee)是父子关系。而协程不同,协程之间是对等关系,每个协程都有一个调用栈。协程有非对称和对称两种实现,非对称协程使用 resume 和 yield 关键字,调用者使用 resume 恢复某个协程,被调用者使用 yield 暂停当前协程,然后控制会转移到调用者。对称协程只使用 yield 关键字,但是需要指定将控制转移给哪个协程。经典的例子,比较两个二叉树是否包含相同的序列(中序遍历),代码。
协程的控制转移是主动的(非抢占式),不需要操作系统支持,也不需要使用锁和信号量等同步原语。线程的控制转移是被动的(抢占式),由操作系统调度,上下文切换更加昂贵,需要使用同步原语保护共享变量。协程只提供并发性,而线程可以利用多核 CPU 实现并行。切换的速度,协程最多 10 纳秒,线程几微秒,Goroutines 和 Virtual Threads(Java 21) 几百纳秒。
网络上各种术语的解释很混乱,根据多线程模型,我倾向于使用用户线程和内核线程的对应关系,来描述不同的实现。简单描述一下我的理解:平常使用的是一对一模型,Goroutines 和 Virtual Threads 使用的是多对多模型。协程不能简单的看作多对一模型,协程是非抢占式的用户线程,描述的是多个用户线程之间的协作关系,实际上可以在各个模型上实现协程。
关于 Goroutines 的实现,可以看 Dmitry Vyukov 的演讲 Go scheduler: Implementing language with lightweight concurrency。其他资源:Scalable Go Scheduler Design Doc,The Go scheduler,HACKING。
简单的设计,使用一对一模型 + 线程池,缺点是线程的内存占用较大,Goroutine 阻塞会导致线程阻塞,没有“无限数量”的栈。所以,使用多对多模型,Goroutine 占用内存更小,可以被 Go runtime 完全控制。如果 Goroutine 因为锁/通道/网络 IO/计时器而阻塞,Goroutine 将会进入阻塞队列,运行此 Goroutine 的内核线程不会阻塞,Go runtime 可以从 Run Queue 中调度 Runnable 的 Goroutine 到该内核线程上(复用,Multiplex)。
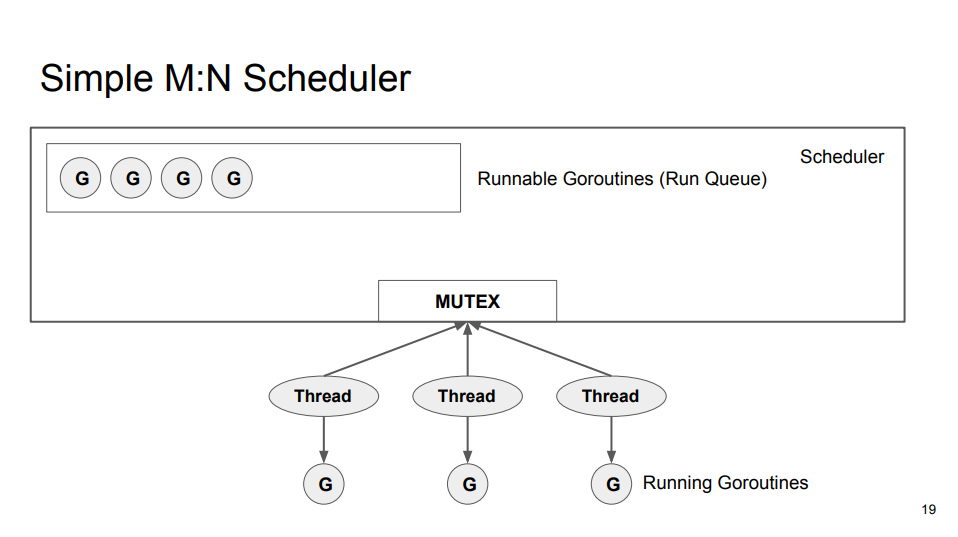
但是,当 Goroutine 进行系统调用,控制将从 Goroutine 转移到系统调用处理程序,Go runtime 是无法感知该处理流程的,直到系统调用返回,所以此时运行 Goroutine 的内核线程是无法被复用的。有可能所有内核线程都阻塞在系统调用上,而该系统调用所需的资源被某个 Runnable 的 Goroutine 持有,从而发生死锁。所以在系统调用发生时总是会创建/唤醒一个内核线程,执行 Run Queue 中的 Goroutine。当内核线程从系统调用返回,Go runtime 将内核线程上的 Goroutine 放入 Run Queue,使该内核线程空闲从而保证指定的并行度(由 GOMAXPROCS 指定)。
关于 GOMAXPROCS,runtime 文档的描述如下:The GOMAXPROCS variable limits the number of operating system threads that can execute user-level Go code simultaneously. There is no limit to the number of threads that can be blocked in system calls on behalf of Go code; those do not count against the GOMAXPROCS limit.
该实现的瓶颈在全局的互斥锁(MUTEX),内核线程创建 Goroutine 以及获取 Goroutine 都需要操作共享的 Run Queue。解决方案很容易想到,就是为每个内核线程创建本地变量,从而避免频繁访问全局的共享变量。该方案会增加获取下一个 Goroutine 的复杂性,Go 调度器实现的获取顺序是, Local Run Queue、Global Run Queue、Network Poller、Work Stealing。
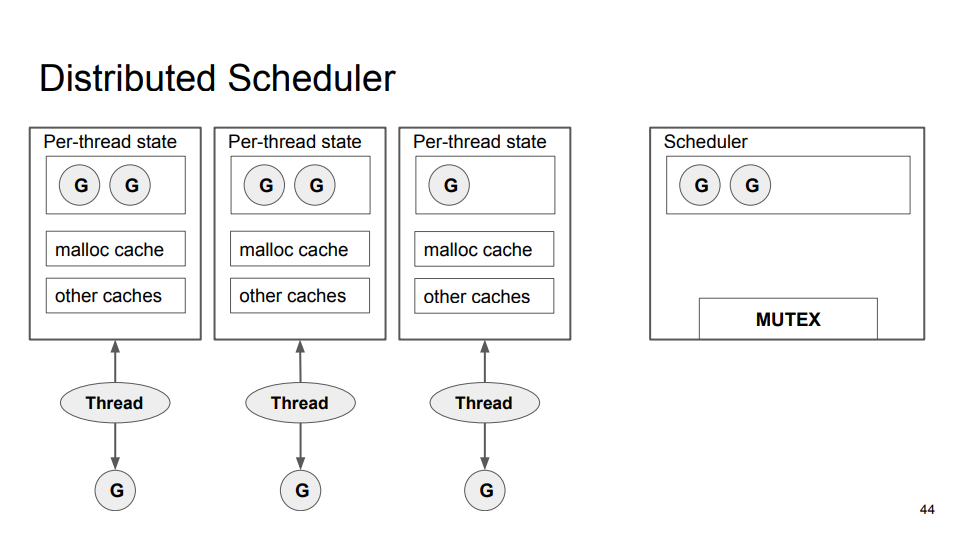
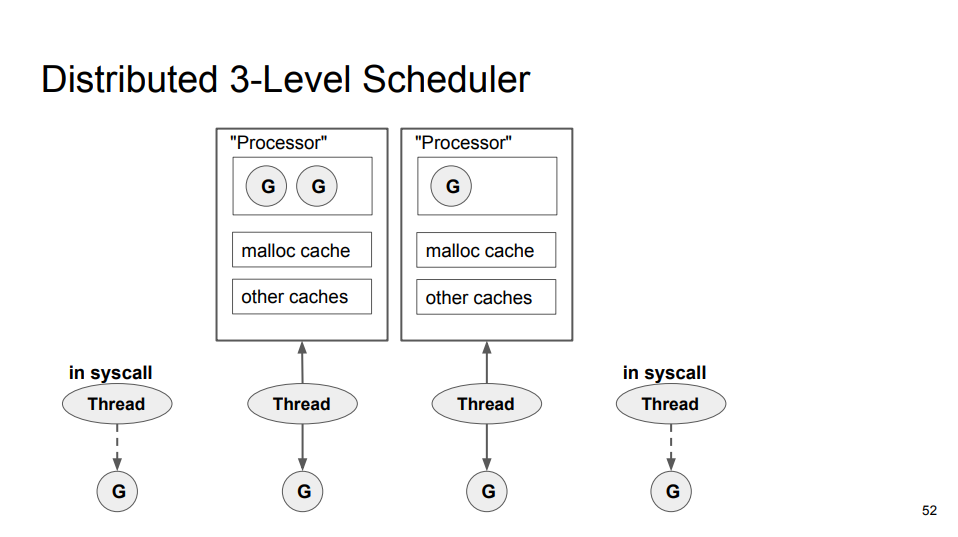
由于发生系统调用时会创建/唤醒内核线程,也就是说内核线程的数量会多于 CPU 的核心数量。新的调度器为每个内核线程分配本地资源,但是实际上执行 Go 代码的内核线程的数量是固定的(由 GOMAXPROCS 指定),所以空闲线程不应该持有资源,会造成资源浪费以及降低 Work Stealing 的效率。所以,设计上引入一个新的实体,也就是处理器(Processor),从而调度模型从 GM 变为 GMP。Go runtime 不会为每个内核线程分配资源,而是为 Processor 分配资源,Processor 的数量就是 CPU 的核心数量。在新的模型中,当 Goroutine 发生系统调用时,Goroutine 会创建/唤醒新的内核线程,然后将 Processor 对象交给新的内核线程。
目前,调度器已经足够好,不过可以更好。公平性(Fairness)和性能的权衡:设计者想要以最小的性能开销获得最小的公平性。FIFO 队列可以一定程度上保证公平性,但是如果当前 Goroutine 陷入无限循环,队列中的 Goroutine 将会饥饿,所以设计者使用 10 ms 的时间片轮转调度(时分共享,抢占式)。另一方面,FIFO 队列缺少局部性(影响性能),最后进入队列的 Goroutine 会在最后运行。常见的场景,当前 Goroutine 创建另一个 Goroutine,然后自身被阻塞等待另一个 Goroutine 执行。缺少局部性的 FIFO 会产生很大延迟,所以设计者在 Local Run Queue 的尾部添加一个单元素的 LIFO 缓冲区,每次获取 Goroutine 都会首先从缓冲区中获取(Direct Switch)。
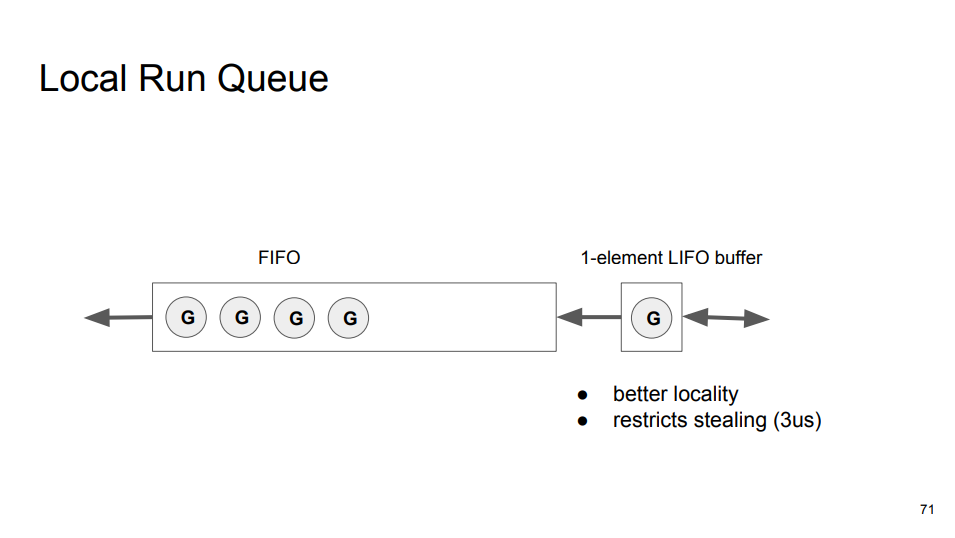
该设计引入额外两个问题,一个是其他内核线程从当前内核线程 Work Stealing 时,将 LIFO 中的 Goroutine 窃取,影响 Direct Switch 的执行。解决方案是只有 Goroutine 被放入 LIFO 超过 3 μs 才能被窃取。另一个问题是,不断创建 Goroutine 会导致 LIFO 缓冲区总是有元素,从而 FIFO 队列中的 Goroutine 会饥饿,解决方案是当前 Goroutine 和 LIFO 中的 Goroutine 共享同一个 10 ms 的时间片。
如果 Local Run Queue 一直不为空,Global Run Queue 会饥饿。所以,假设当前是第 schedTick 次获取,设计者设置当 schedTick % 61 == 0 时,优先从 Global Run Queue 获取 Goroutine。为什么使用 61,因为 61 不大不小,太大会饥饿,太小会因为 Global Run Queue 的 MUTEX 限制性能,并且参考哈希表的设计,使用质数而不是 2 的幂会更随机/公平。

最后,Network Poller 可能会饥饿,解决方案是使用后台线程从中定期获取 Goroutine。之所以不像处理 Global Run Queue 饥饿一样在当前线程中获取,是因为从 Network Poller 获取 Goroutine 涉及到 epoll_wait() 系统调用(很慢)。